
Introduction
In 2016, Scientific Data published a paper titled The FAIR Guiding Principles for scientific data management and stewardship, a call-to-action and roadmap for better scientific data management. The mission was clear: provide digital information with the characteristics it needs to be found, accessed, interoperable, and reused by communities after initial data publication. FAIR principles allow data and metadata to power insights across its many stakeholders and evolve into dynamic sets of shared knowledge:
Bringing FAIR to the Enterprise
As noted by the initial paper, FAIRness was born out of the data management pains apparent in the scientific research community -- specifically the need to build on top of existing knowledge and securely collaborate on research data. But the FAIR principles should now be considered for highly-sophisticated master data management across various industries, especially as enterprises begin to invest heavily in extracting analytical and operational value from data.
Today’s enterprise data has multiple stakeholders - front-office applications that generate data, compliance departments, ERP systems, cybersecurity, back-office analysts, and emerging technology projects like AI, among many others. With this degree of layered collaboration, FAIR data principles should be implemented to extend data’s utility across the data value chain and provide an enterprise-wide source of truth.
Building FAIR data directly in as an immediate requirement across all data assets might seem like an extreme upfront investment versus your standard data management procedure of hiring data scientists to extract value from old data, but as semantic data expert Kurt Cagle so eloquently states in a recent publication titled “Why You Don’t Need Data Scientists”:
“You have a data problem. Your data scientists have all kinds of useful tools to bring to the table, but without quality data, what they produce will be meaningless.”
Kurt Cagle
FAIR data is about prescribing value to information at the source of creation, rather than as a messy afterthought of harmonizing, integrating, and cleansing data to be further operationalized in yet another silo.
With data integration, compliance, and security as the top items consuming the typical IT budget, perhaps starting with FAIR data is worth the upfront investment. And as superior Master Data Management becomes a competitive edge in 2020, FAIR data principles must be considered beyond the scope of the research industry.
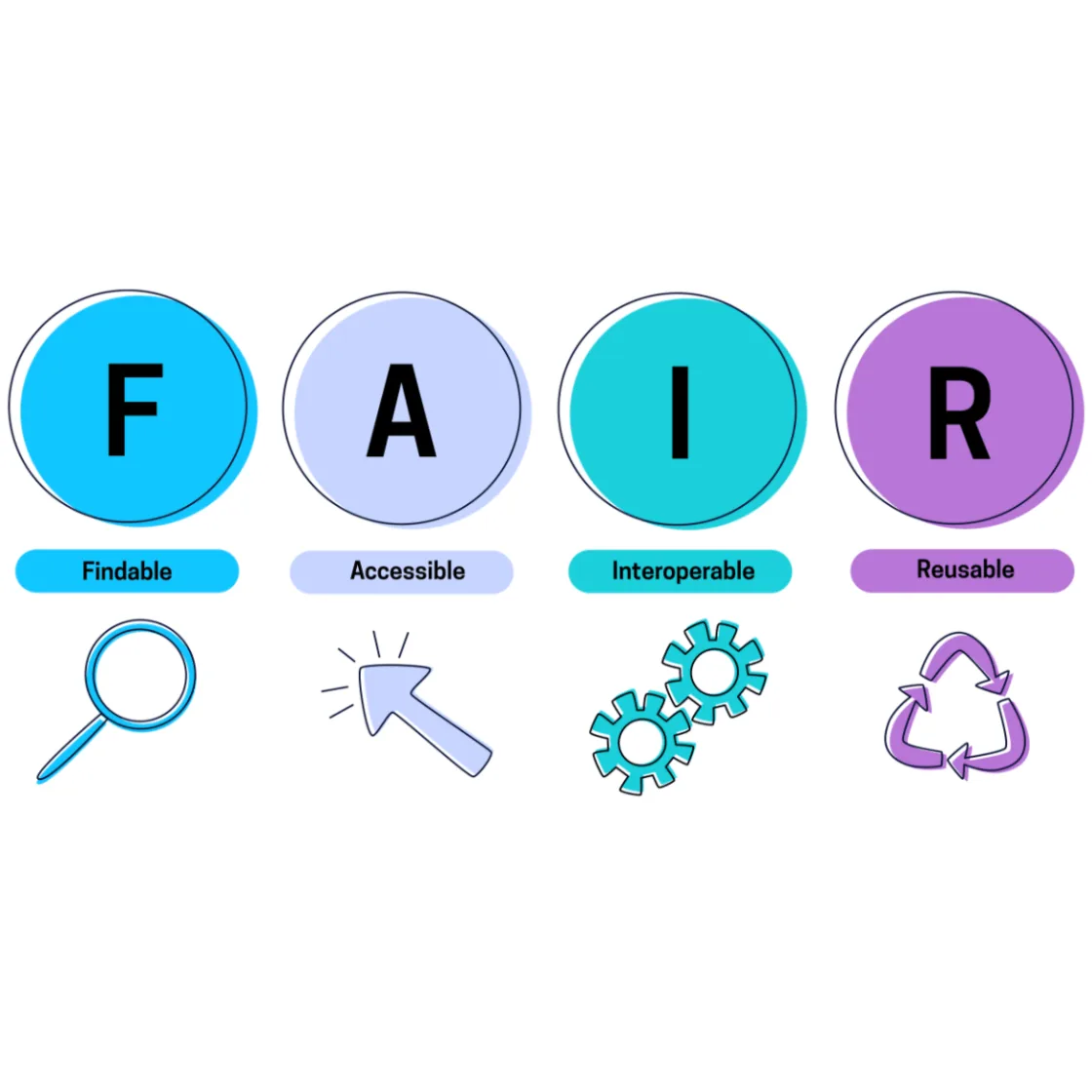
So, what makes data “F.A.I.R.”?
FAIR data principles not only describe core standards for data and metadata, but also for tools, protocols, and workflows related to data management. Let’s dive in:
(Thanks to go-FAIR: https://www.go-fair.org/fair-principles/)

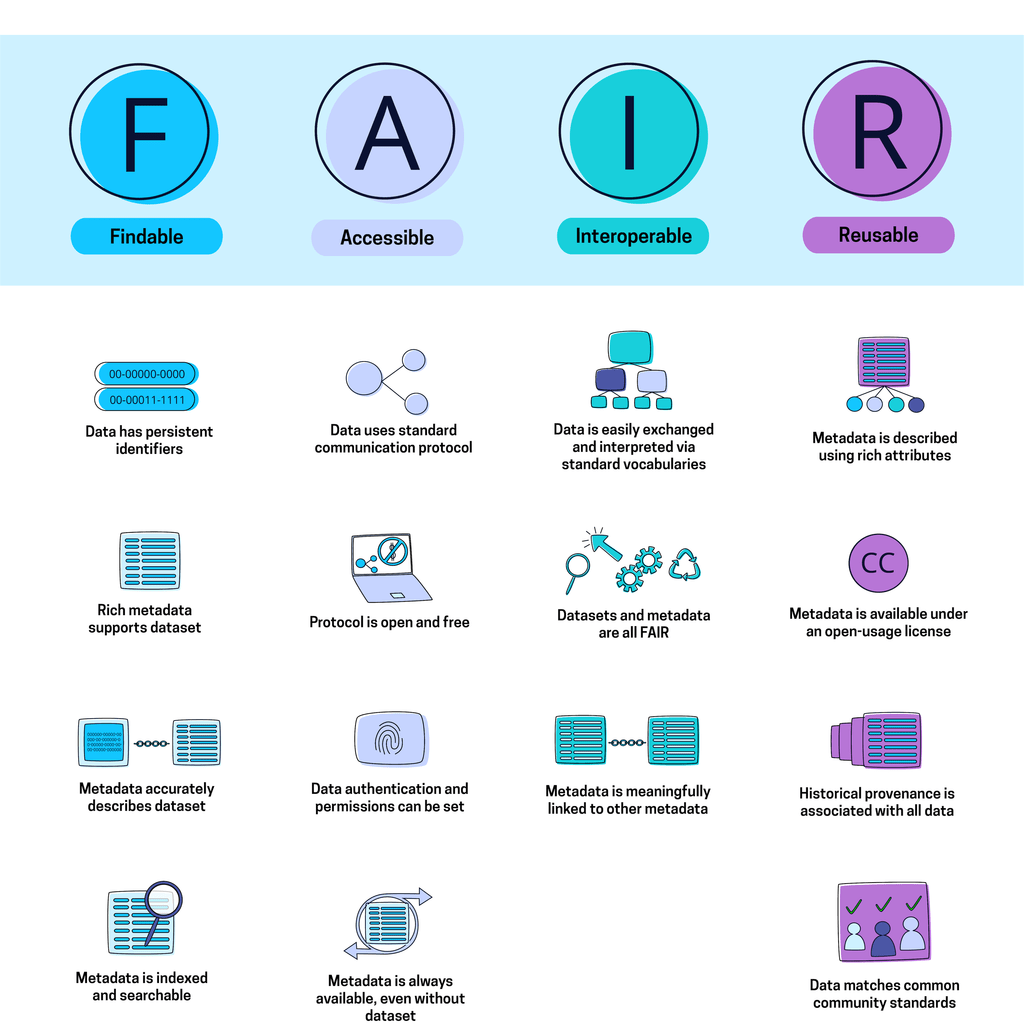
Findable
Findability is a basic minimum requirement for good data management but can be often overlooked when rushing to ship products. In order to operationalize data, humans and machines must first be able to find it -- this comes down to utilizing rich, schematically-prescribed metadata to describe information so consumers know where and how to look.
- Data has persistent identifiers - A unique identifier for every data element is essential for humans and machines to understand the defined concepts of the data they are consuming.
- Rich metadata supports dataset - Provide as much supporting metadata as possible for future stakeholders to find it via linked data. Rich and extensive details about data might seem unnatural to the standard database programmer but can seriously boost findability downstream as your web of data assets grows.
- Metadata accurately describes dataset - A simple yet important rule for scaling knowledge: metadata’s relationship to a dataset should be defined and accurate.
- Metadata is searchable - Metadata must be indexed correctly in order for data to be a searchable resource.
Accessible
Once data can technically be found, it must now be accessible to its various stakeholders at the protocol layer, with data access controls baked in.
- Data uses a standard communication protocol - Data should be able to be retrieved without proprietary protocols. This makes data available to a wider range of consumers.
- The protocol is open and free - Reinforcing the above, the protocol should be universally implementable and non-proprietary. (These may change depending on open/closed enterprise environments, but most data must scale outside enterprise borders. )
- Data authentication and permissions can be set - Data ownership, permissions and controls should be comprehensively integrated into FAIR data strategies - because data is technically accessible to all via an open protocol, we must ensure a scalable Identity and Access management system. (Note: Take a look at Fluree’s Data-Centric Security here!)
- Metadata is always available, even without dataset - Metadata must persist even in the event that data is deleted in order to avoid broken links. Metadata is an incredibly valuable asset and should be treated as such.

Interoperable
Data must be primed for integration with other data sets and sources. Data must also be consumable via any standards-based machines.
- Data is easily exchanged and interpreted via standard vocabularies - Data must be consumable for both machines and humans, therefore it is imperative to represent it within a universally-understood data ontology and within a well-defined data structure. For example, Fluree stores every piece of data and metadata in W3C-standard RDF format - an atomic triple readily consumable by virtually every machine.
- Datasets and Metadata are all FAIR - The vocabularies that govern these principles must adhere to FAIR principles.
- Metadata is meaningfully linked to other metadata - In order to extend the value of linked data, the relationship between metadata should be cross-referenced in rich detail. This means that instead of stating “x is associated with y” one might state “x is the maintainer of y”
Reusable
The first three characteristics (FAI) combine with these last properties to ultimately make data reusable as an operational resource for apps, analytics, data sharing, and beyond.
- Metadata is described using rich attributes - Data must be described with a plurality of labels, including rich descriptions of the context in which the data originated. This allows for data not only to be found (see F), but also understood in context to determine the nature of reuse.
- Metadata is available under an open-usage license - In order to be re-used, data must come with descriptive metadata on its usage rights.
- Historical Provenance is associated with Metadata - We must understand the full provenance and path of data in explicitly published traceability in order to effectively reuse data and metadata. For example - Fluree automatically captures traceability and can output a complete audit trail of data - including details of origination and path of changes tied to unique user identities in an immutable chain of data events.
- Data matches common community standards - If relevant, data must adhere to domain-specific standards. For example, the FHIR standard for healthcare interoperability or GS1 standards for supply chain interoperability.
Taking the Fluree Approach
Fluree’s semantic graph database expresses information in W3C standard RDF formatting and extends metadata capabilities to comprehensively satisfy F.A.I.R. requirements:
- RDF Data Format; Extended with Timestamp for Provenance
- Semantic Graph Format with SPARQL Support for Leveraging Data Sets
- Data-Centric Security and Permissions for Data-Level Access Control
- Complete Data History Logged with Blockchain Traceability and Proof
- Data-Centric Functions to Enforce Schema-Level Governance and Data Framework Compliance
To most people, databases are simply tools built to feed an application. But at Fluree, we are reimagining the role of the database to acknowledge functions beyond data storage and retrieval. Fluree is not just a read-only data lake, but also a transactional engine. In essence, Fluree’s data platform can build sets of FAIR data, enforce ongoing compliance to FAIR data standards with governance-as-code, and power consumers of FAIR data for read/write applications.
More on Fluree’s Data-Centric features here: /solutions/enterprise-knowledge-graph
Further Reading on FAIR Data Principles:
Stay in the loop
Weekly insights on enterprise AI, knowledge graphs, and data intelligence.