Blog
Insights & Updates
Thought leadership on enterprise AI, knowledge graphs, product updates, and engineering best practices.
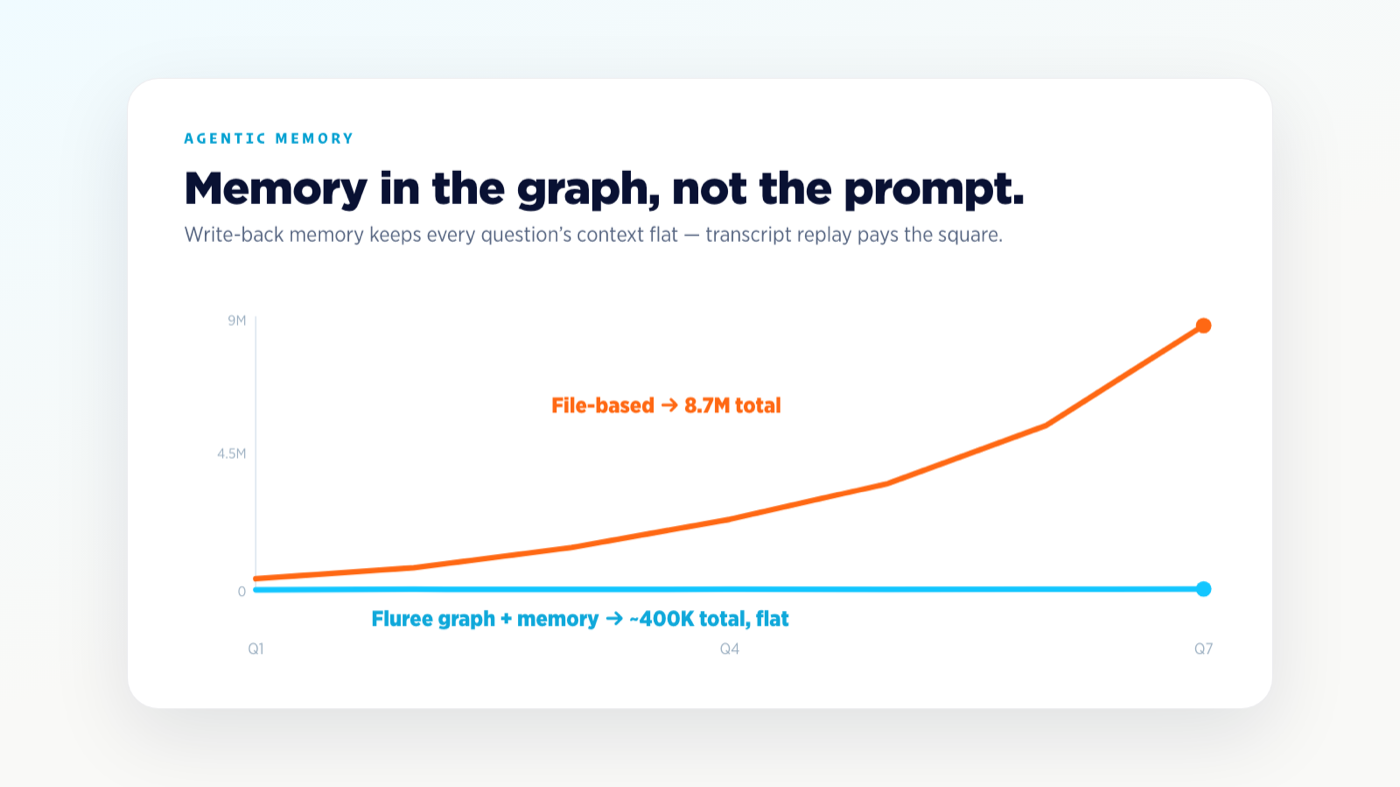







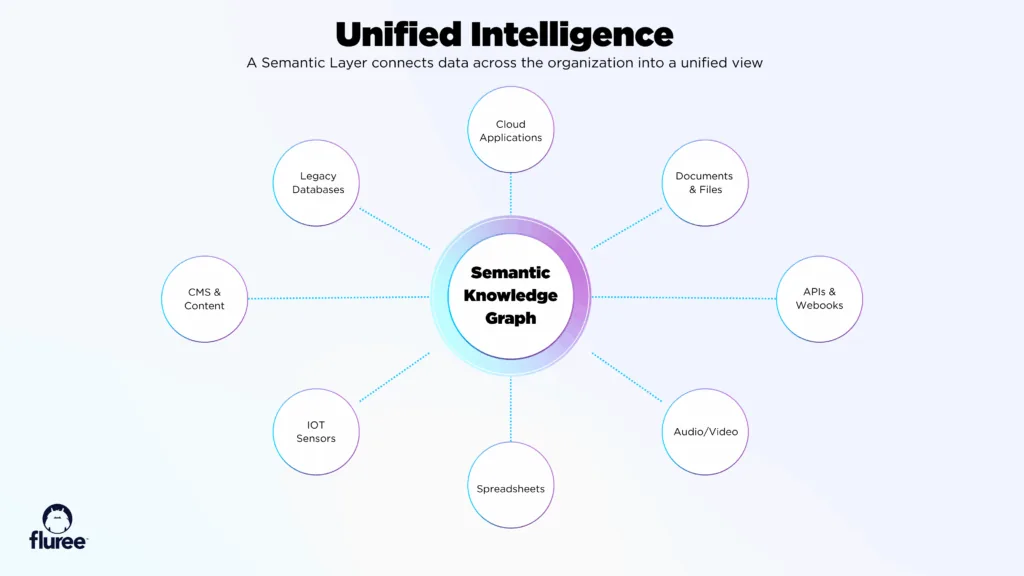
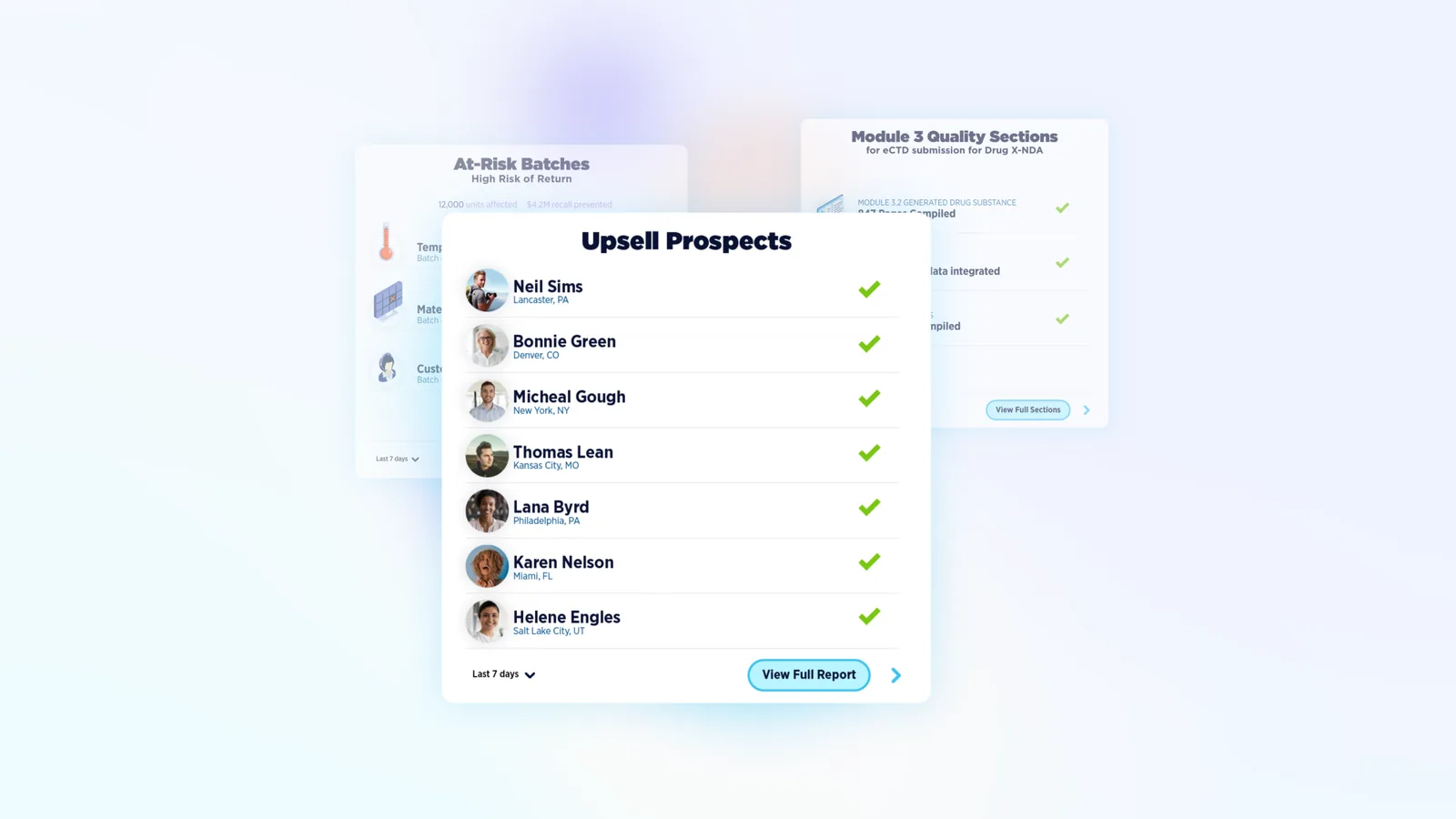



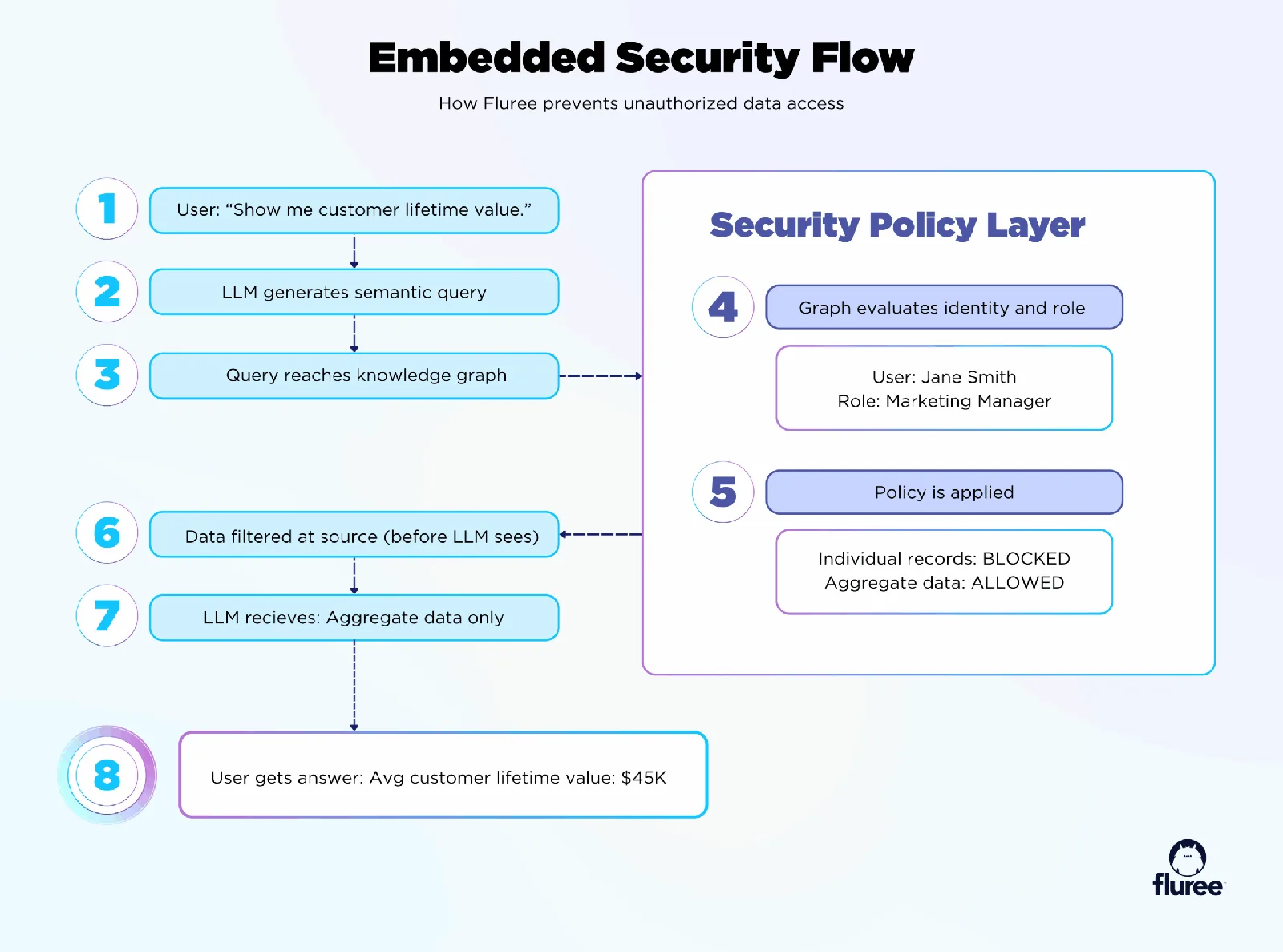
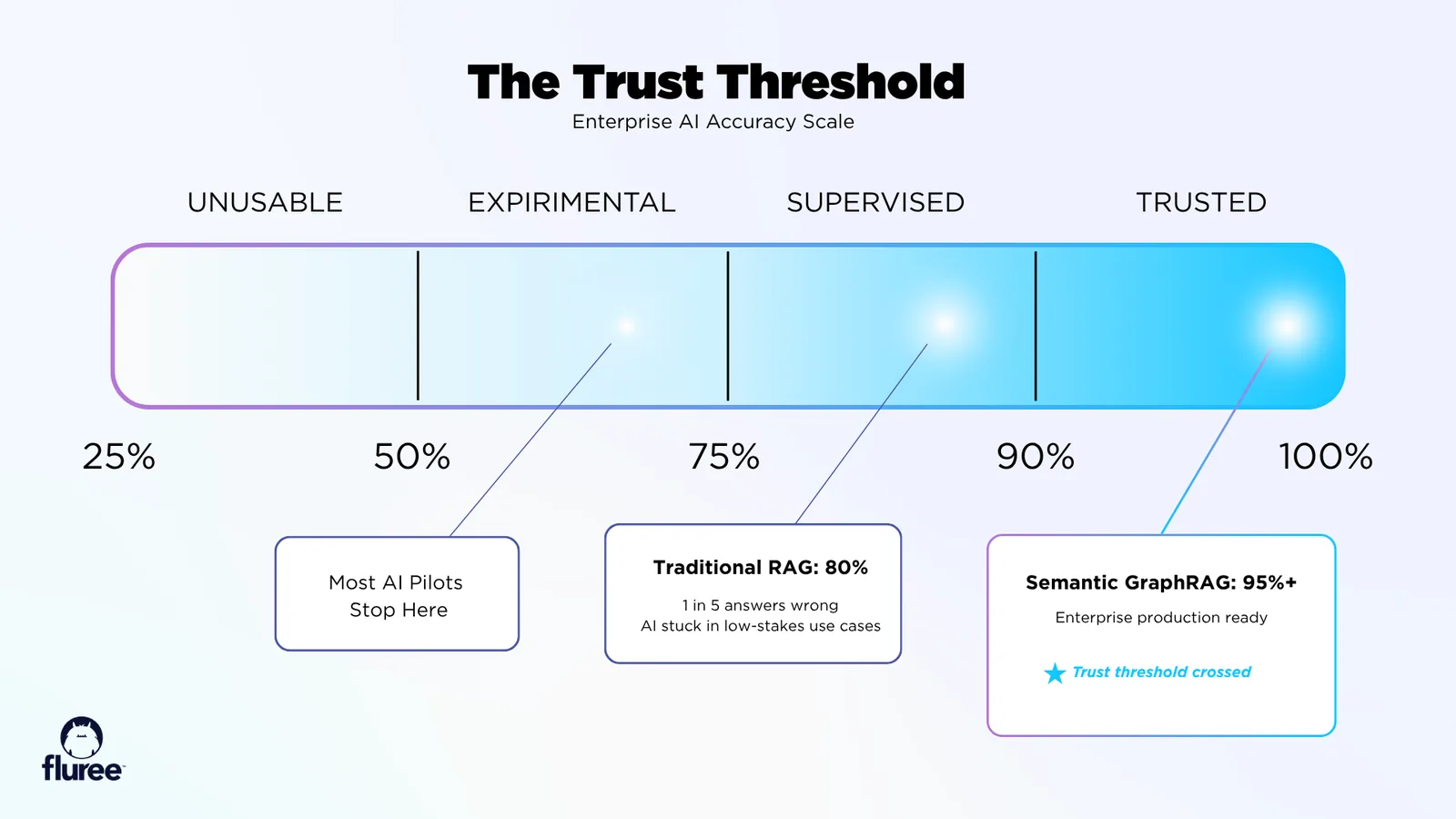
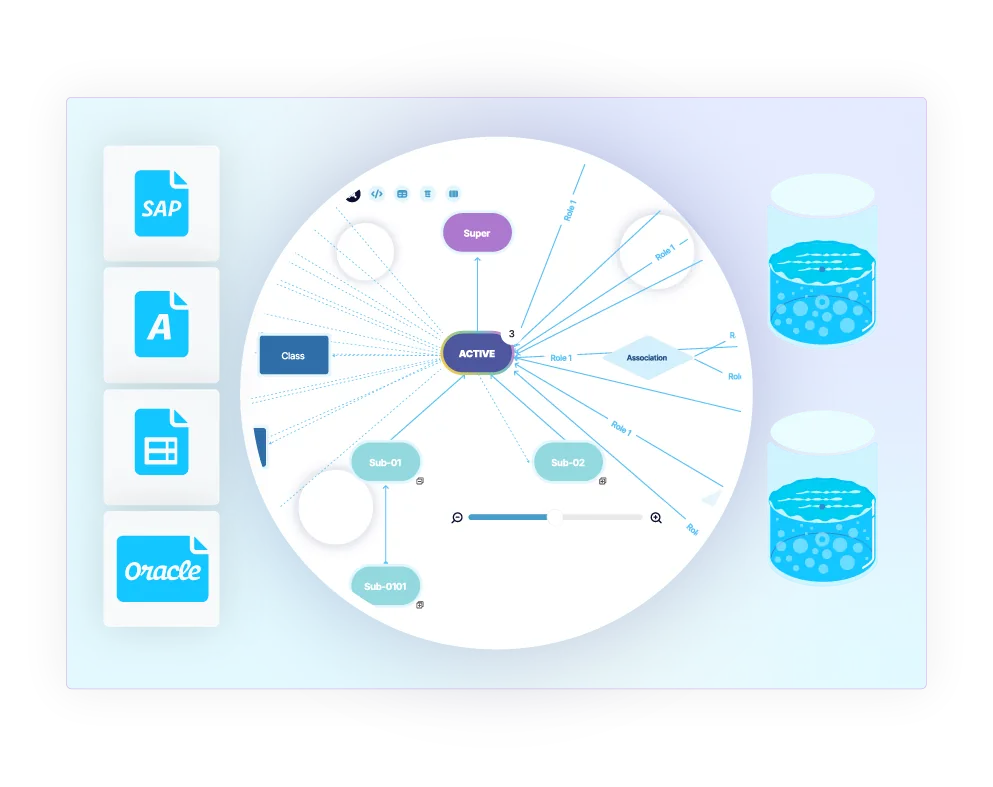

Free weekly newsletter
Stay ahead of the curve
Weekly insights on enterprise AI, knowledge graphs, and data intelligence — straight to your inbox.