What is an Immutable Database?


Data immutability refers to a principle where information in a database is permanent and cannot be altered or removed. In these immutable, or append-only, databases, new data can only be appended. This approach ensures that an immutable database never modifies or overwrites existing entries, even when new information comes in. If an error occurs, it is rectified by adding a new entry, not by changing the existing one.
Think of it as a digital ledger with entries that are set in stone. Each new entry gets appended to the existing data, preserving a permanent history of every change. Changes are easy to track, offering clear audit trails.
How Does An Immutable Database Work?
Typical databases are mutable – meaning that any change to an existing record automatically erases the previous record. Immutable databases store records in logs, and create a new log with every update.
This means immutable databases are “append-only,” meaning that every update or correction creates a new historical record. The original entry is preserved as its own historical record, and can be accessed through an audit (in Fluree, we provide time travel queries that can specify a walk-clock time or a “block” to retrieve data as-of any moment in time.)
Immutable databases use cryptographic signatures and temporal metadata to record important information about the ledger of changes: when a record was created, updated, and pointers to previous versions. The new entry is hashed and cryptographically tied to the hash of the previous entry:
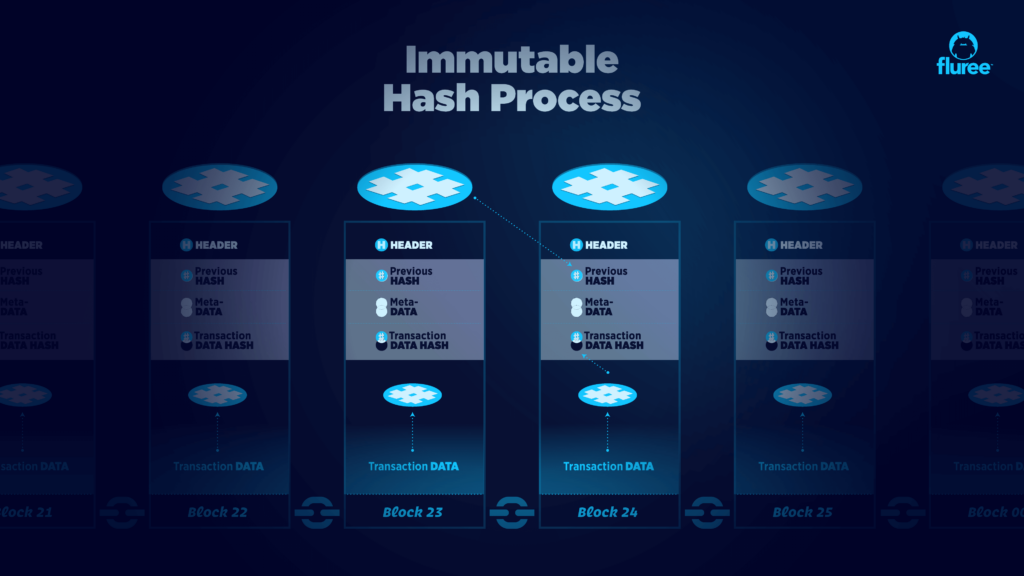
Data in your immutable database is thus indelible, reproducible, and auditable.
Why use an Immutable Database?
Effective data management is becoming a priority for organizations -- both defensively (risk & audit) and offensively (analytical capacity, effective AI). From fighting the incoming onslaught of data poisoning attacks for trusted generative AI to preventing data loss and ensuring data compliance, immutable databases offer an excellent solution.
- Data Integrity and Compliance: With an immutable structure, the risk of accidental data deletions or unauthorized changes diminishes. This ensures that the data remains intact and trustworthy over time, and ensures compliance with any kind of data request.
- Audit Trail: For businesses that need to maintain a record of all transactions or changes—like in finance or healthcare—an immutable database offers a transparent and complete history. Preserving historical data can come in handy for highly-regulated industries.
- Enhanced Security: Immutable databases are resilient against data tampering (sometimes known in the ML world as data poisoning). Using an immutable database that tracks historical changes can fight against falsified or tampered data, ensuring trusted information is accessed and used.
- Historical Queries -For developers and business users alike, immutable databases provide a straightforward solution to questions like "What changes has this entity undergone over time?" or "What was the result of this query three weeks ago?" With an immutable database, these insights into your data’s evolution over time are readily available without the need for any extra engineering effort.
The Storage and Performance Concern
Since data can only be appended and not deleted, the most frequent concern when selecting immutable databases is, of course, storage (am I really storing a new database every single time there is an update?) and performance (how do I handle a complex query across potentially thousands of "databases?"). The answer to this potential issue relies on efficient indexing:
Fluree simply stores the deltas of new transactions and efficiently indexes them through a temporal value. When Fluree is working through slices of time, each "time" is just a delta sitting on top of a reference time - and the common pieces of data are all shared via pointers in memory.
Say you wanted to see the results of a query as of midnight for every day of the year, for the past 3 years. That is technically over 1,000 distinct databases you’d be querying. While you get the benefit of it seeming like you can query 1,000 distinct backups of your db, the machine is just representing deltas against some reference time - and a piece of data is never duplicated. The actual impact of this might be a 5% increase in memory, not the 1,000x one might think it would require.
How will you use an Immutable Database?
Are you looking to lock in time for a query? Provide historical insights for analytics? Preserve audit-friendly digital records? Immutable databases might just be your preferred tool.
If you’re looking to take advantage of immutable data, check out Fluree. Fluree is an open-source immutable graph database that enables time travel queries, historical queries, and verifiable data out-of-the-box. Read more in our documentation or get started here.
Stay in the loop
Weekly insights on enterprise AI, knowledge graphs, and data intelligence.