Introduction to Data-Centricity


Welcome to Fluree’s series on data-centricity. Over the next few months, we’ll peel back the layers of the data-centric architecture stack to explain its relevance to today’s enterprise landscape.
Data-centricity is a mindset as much as it is a technical architecture - at its core, data-centricity acknowledges data’s valuable and versatile role in the larger enterprise and industry ecosystem and treats information as the core asset to enterprise architectures. Opposite of the "Application-Centric" stack, a data-centric architecture is one where data exists independently of a singular application and can empower a broad range of information stakeholders.
Freeing data from a single monolithic stack allows for greater opportunities in accelerating digital transformation: data can be more versatile, integrative, and available to those that need it. By baking core characteristics like security, interoperability, and portability directly into the data-tier, data-centricity dissolves the need to pay for proprietary middleware or maintain webs of custom APIs. Data-Centricity also allows enterprises to integrate disparate data sources with virtually no overhead and deliver data to its stakeholders with context and speed.
Data-Centric architectures have the power to alleviate pain points along the entire data value chain and build a truly secure and agile data ecosystem. But to understand these benefits, we must first understand the issues of “application-centricity” currently in place at the standard legacy-driven enterprise.
Big Data** ≠ **Valuable Data
The application boom of the ’90s led to increased front-office efficiencies but left behind a wasteland of data-as-a-byproduct. Most application developers were concerned with one thing: building a solution that worked. How the application data would be formatted or potentially reused was secondary or perhaps out of sight.
Businesses quickly realized that their data has a value chain - an ecosystem of stakeholders that need permissioned access to enterprise information for business applications, data analysis, information compliance, and other categories of data collaboration. So, companies invested in building data lakes - essentially plopping large amounts of data, in its original format, into a repository for data scientists to spend some time cleansing and analyzing. But these tools simply became larger data silos, introducing even higher levels of complexity.
In fact, 40% of a typical IT budget is spent simply on integrating data from disparate sources and silos. And integrating new data sources into warehouses can take weeks or months - which is a far cry from becoming truly “data-driven.”
In the application-centric framework, data originates from an application silo and trickles its way down the value chain with little context. To extract value from this data is a painful or expensive process. Combining this data with other data is an almost impossible task. And delivering this data to its rightful value chain is met with technical and bureaucratic roadblocks.
These are not controversial claims. According to an American Management Association survey, 83% of executives think their companies have silos, and 97% think it’s having a negative effect on business.
Let’s explore how these data silos continue to proliferate, even after the explosion of cloud computing and data lake solutions:
The Application-Centric Process
Today, developers build applications that, by nature, produce data.
Middle and back-office engineers build systems to collect the resultant data and run it through analysis, typically in a data lake or warehouse.
Data governance professionals work to ensure the data has integrity, adheres to compliance, and can be reused for maximum value.
In order to re-use or share this data with third parties or another business app, it needs to go through processes of replication, cleansing, harmonization, and beyond to be usable. Potential attack surfaces are introduced at every level of data re-use. Complexity constrains the data pipeline with poor latency and poor context.
In other words, data is not armed at its core with the characteristics it needs to provide value to its many stakeholders -- so we build specialized tools and processes around it to maximize its analytical value, prove compliance, share it with third parties, and operationalize it into new applications. This approach may have worked for ten or so years - but the data revolution is not slowing and these existing workaround tools cannot scale. Our standard ETL process is slow and expensive, and data lakes become data silos with their own sets of compliance, security, and redundancy issues.
But there is a better way - a path to data-centricity - that flips the standard enterprise architecture on its head and starts with an enterprise’s core asset: data.
The Shift to Data-Centricity - Why Now?
Industries are moving towards data ecosystems - an integrative and collaborative approach to data management and sharing. Here are just a few examples:
- Data-driven business applications today touch many internal and external stakeholders (sales, HR, marketing, analysis, compliance, security, customers, third parties, etc.). There is a clear need to collaborate more effectively and dynamically on data that powers multiple applications across multiple contexts.
- Enterprises are building (many for the very first time) a master data management platform for a 360-degree-level view of their master data assets. This can be as simple as building a “golden record” customer data repository to cut down on redundancies in data silos and implement more centralized data access rules. Next-generation MDM solutions are now making their “golden record” repositories operational - where their master data repositories directly power applications and analysis from the same source of truth. Data-centricity is essential here.
- Enterprises are creating data “knowledge graphs” that link and leverage vast amounts of enterprise data under a common format for maximum data visibility, analytics, and reuse.
- More advanced enterprises are building “data fabrics,” a hyper-converged architecture that focuses on integrating data across enterprise infrastructures. Data Fabrics (in theory) provide streamlined and secure access to disparate data across cloud and on-prem deployments in an otherwise complex distributed network environment.
- Enterprises are realizing the value of “data marketplaces,” where “golden record” information can be subscribed to within a data-as-a-service framework.
To accommodate these data-driven trends, we need to build frictionless pipelines to valuable data that is highly contextual, trusted, and interoperable. And we need to answer emerging questions around data such as:
- Data Ownership: Who owns the data, and how is privacy handled?
- Data Integrity: How do we know the data has integrity?
- Data Traceability: Who/When/How was it originally put into the system? How has that data changed over time, and who has accessed that data?
- Data Access Permissions: Who should be able to access the data or metadata, and under what circumstances? How can we change those security rules dynamically?
- Data Explainability: How do we trace back how machines arrived at specific data-driven decisions?
- Data Insights: How can we organize our data to maximize value to its various stakeholders?
- Data Interoperability: How do we make data natively interoperable with machines and applications that reside within and outside of our organization?
Fluree: The Data-Centric Stack
Fluree is a data management platform that extends the role of the traditional database to answer these above questions. Fluree breaks its core "data stack" into 5 key areas: trust, semantic interoperability, security, time, and sharing.
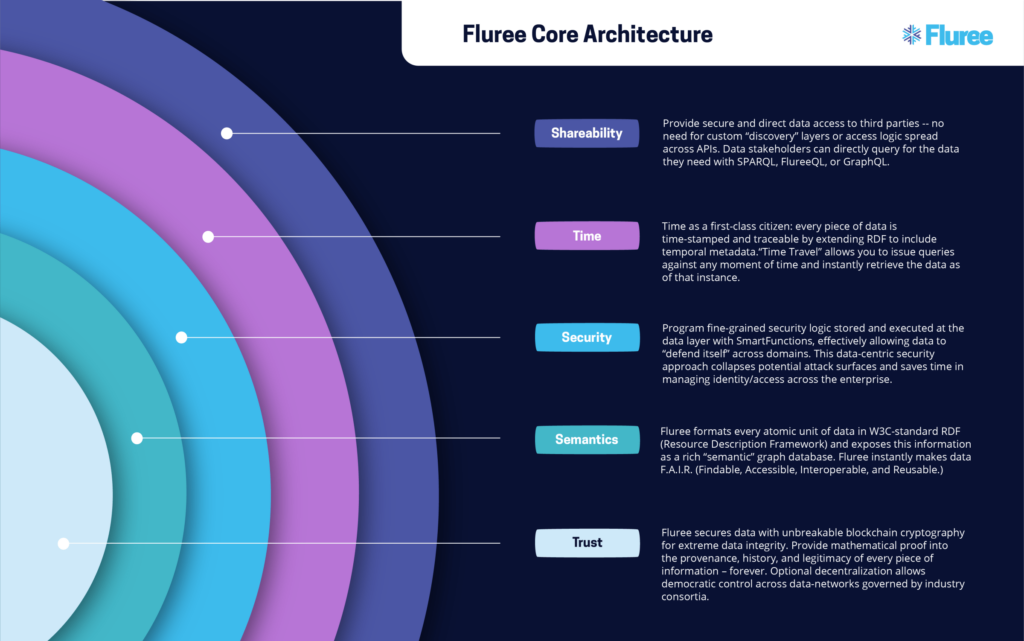
Is Fluree a database, a blockchain, a content delivery network, or a more dynamic, operational data lake?
It seems we could silo off Fluree as a technology to fill any of those roles, but its value should be realized in the greater “data value chain” context. Fluree’s data-centric features work together to enable the data environment of any CIO’s, CTO’s, and CDOs’ dreams. Secure data traceability and audit trails. Instant knowledge graph with RDF semantic standards. Blockchain for trusted collaboration. Scalable graph database with in-memory capabilities to power intelligent, real-time apps and next-generation analysis.
But these concepts can feel overwhelming, especially for a business that has always worked in silos of data responsibility. So, we decided to conceptualize each component to the data-centric stack in this 5 part series. Check out part 1 on "Data-Centric Trust."
Stay in the loop
Weekly insights on enterprise AI, knowledge graphs, and data intelligence.