LLMs Are Becoming Less Accurate. Here’s Where Knowledge Graphs Can Help
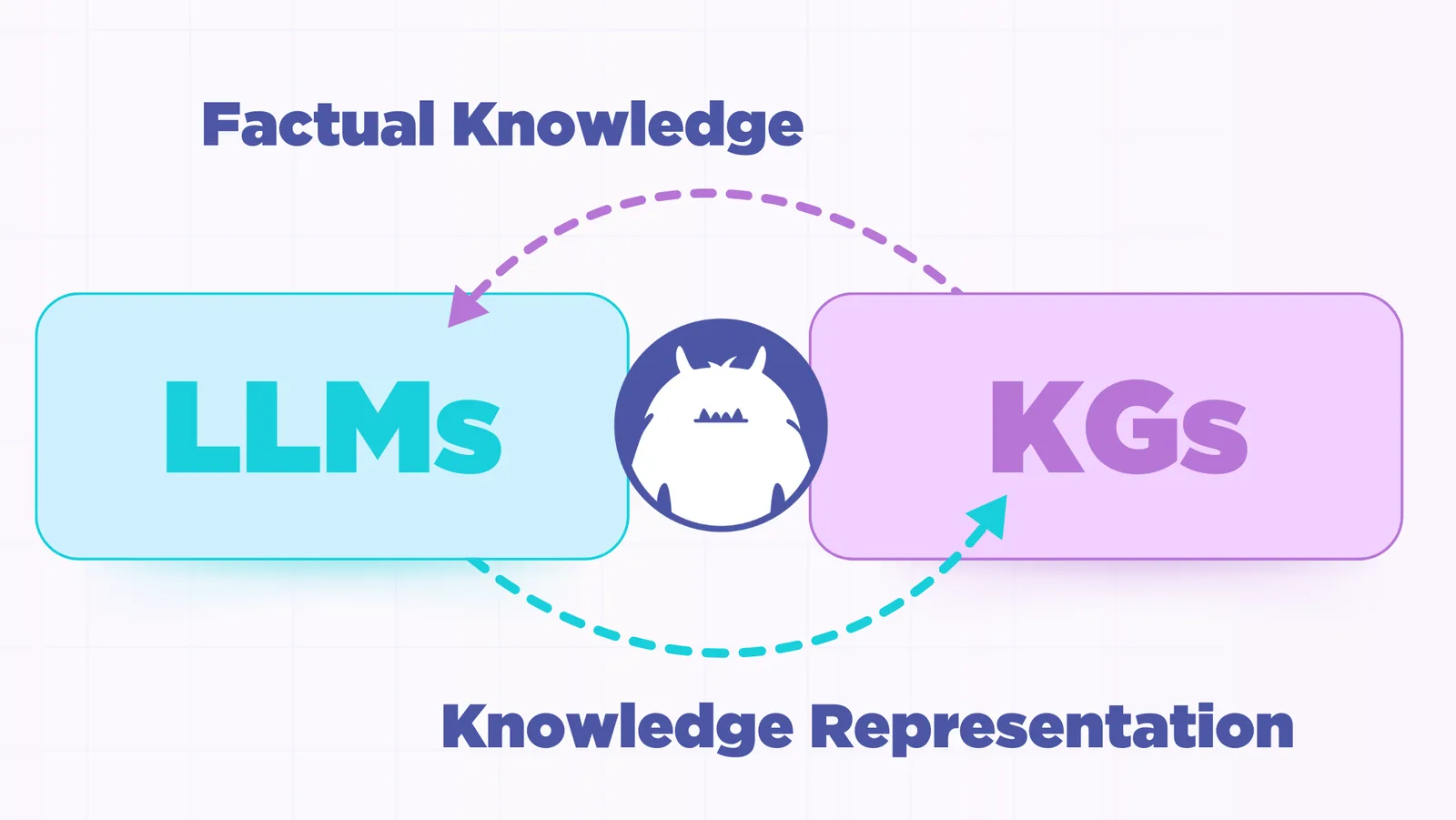
*Image Inspiration Credit: LLMs & Knowledge Graphs, Medium
Large Language Models (LLMs) like GPT-4 have been at the forefront of the recent AI craze, offering jaw-dropping capabilities in (seemingly) understanding and generating human-like text. These models, trained on vast datasets, have demonstrated proficiency in a range of tasks, from writing essays to coding (as well as demonstrating their abilities in passing a final MBA exam, cloning text dialect to automate Whatsapp Responses, and producing a hilarious acceptance speech at the WSJ Innovators Awards).
However, recent findings have brought to light performance inconsistencies in these LLMs.
Studies have indicated fluctuating levels of accuracy and reliability, raising questions about their dependability for critical applications, as highlighted this year in Davos.
For the above light-hearted use cases, this level of model drift may not be problematic. But in high-stake scenarios, where precise and factual information is critical (such as healthcare, supply chain management, financial accounting, or beyond), organizations cannot afford to gamble on accuracy.
Evidence Shows LLMS Become Less Accurate Over Time
A study conducted by researchers at Stanford and Berkeley found that the ability of LLMs to handle tasks like solving mathematical problems and generating code varied significantly over time. The study showed how GPT-4’s accuracy in certain tasks dropped dramatically, showcasing a major concern in the context of LLM reliability.
This variability in accuracy – particularly a downward slope – poses a significant challenge, especially for applications that heavily rely on the consistent and accurate output of these models. The findings underscore the need for solutions to enhance the stability and reliability of LLMs in practical applications.
Why? The Answer is “Fuzzy.”
Open AI’s models are proprietary, so the exact reasons why accuracy is slipping are unconfirmed. However, we can broadly attribute the cause as a cyclical combination of “fuzzy matching” and model drift.
Model drift simply refers to a degradation of performance, due to:
- A changing data environment where the LLM’s original model training becomes less relevant over time.
- Attempts to fine-tune one area of the model while inadvertently causing another area to perform worse
Combined with LLMs’ fuzzy matching approach to answering questions, we can start to see severe implications.
The “fuzzy matching” approach to input/output of a model is grounded in probabilistic modeling, where the LLM generates content based on the likelihood of word sequences as learned from vast datasets. While this allows for fluid and human-like text generation, it inherently lacks a precise understanding of the factual correctness or specific relationships between entities. It simply knows what’s probably next - think “auto-fill” in Google Docs, or suggested text replies on your iPhone, but instead of being trained on just your words, trained on the internet.
The technical basis of this approach lies in machine learning algorithms, particularly neural networks, which process input data (text) and generate outputs based on learned patterns. These models don’t "understand" content in the human sense but rather rely on statistical correlations. This means they can effectively mimic language patterns but may falter when precise, context-specific accuracy is required.
For instance, when asked about specific factual information or nuanced topics, LLMs might produce answers that are plausible but not necessarily accurate. We know this as the “hallucination” crisis.
In scenarios where factual accuracy and consistency are paramount, this probabilistic approach can be a significant limitation, potentially leading to unreliable or misleading information. Combined with the inevitability of model drift, fuzzy matching can pose a serious threat to a business looking to deploy production AI models with sustainable accuracy.
Enter Knowledge Graphs
What is the opposite of “fuzzy matching" when it comes to LLM accuracy? Answer: Explicit, Structured Data.
Unlike fuzzy matching’s probabilistic approach, structured data representation relies on explicitly defined data, definitions, and relationships
This is where knowledge graphs—like Fluree—shine.
Where LLMs might offer ambiguity, Knowledge Graphs offer explicitness.
A Quick Knowledge Graph Refresher
A knowledge graph is a database that represents information as a graph network of entities and relationships between them. They are commonly used for advanced analytics, recommendation systems, semantic search engines, or data discovery, cataloging and integration.
In knowledge graphs, data is represented in the form of semantic objects (or entities), and the connections or relationships between these objects are explicitly mapped. Importantly, they leverage ontologies, which provide formal, structured representations of data and relationships within data.
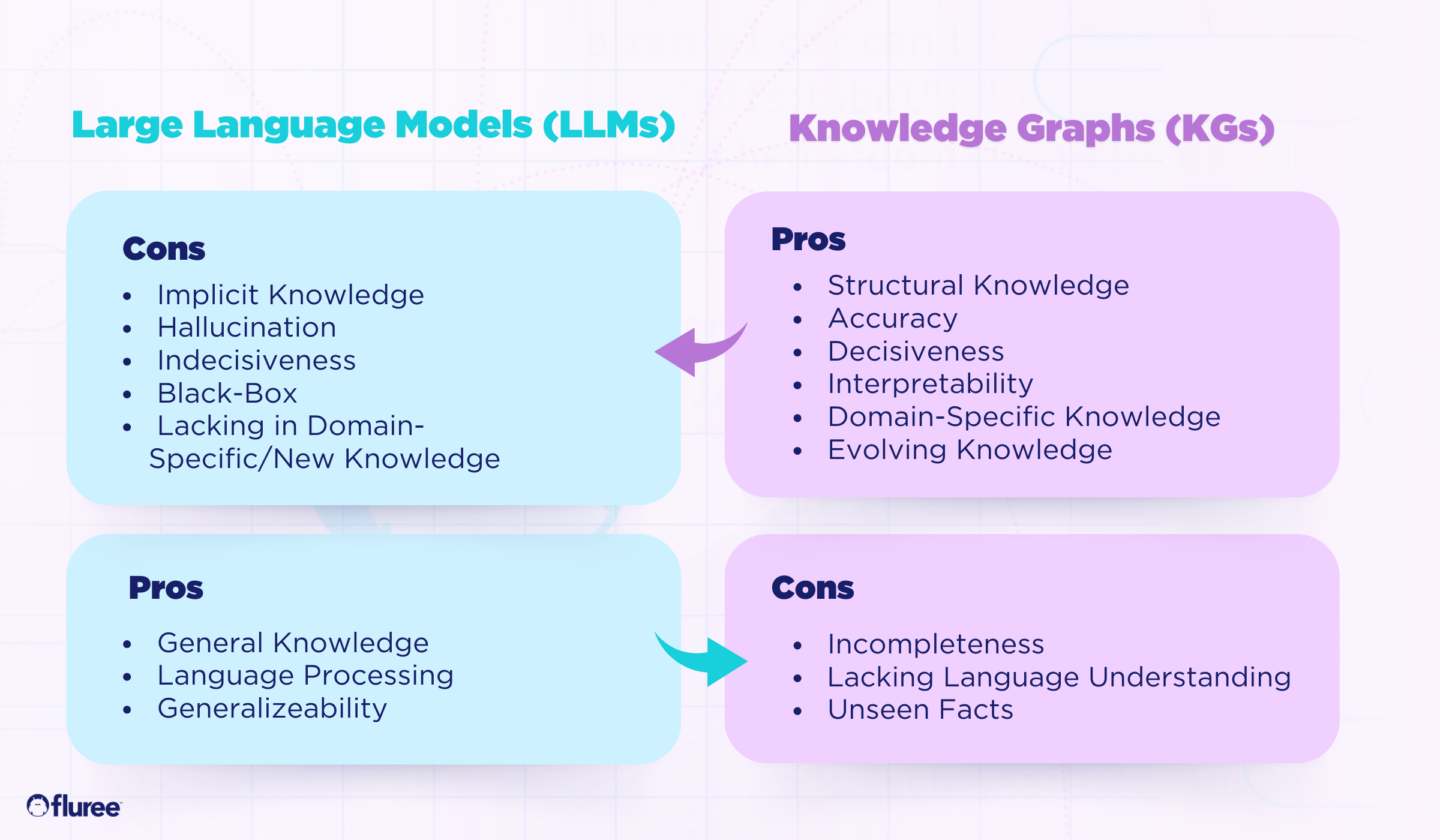
Most important to the matter at hand, knowledge graphs are explicit. They don’t just contain raw data; they define and map the relationships between data points in a global, understandable, and machine-readable way. This explicitness ensures that every piece of information is contextualized, making the data not only more accessible but also more meaningful and reliable. This characteristic of knowledge graphs fundamentally enhances their utility in applications where precision and context are critical.
Explicit Knowledge + LLMs
Knowledge graphs can significantly enhance the accuracy and consistency of LLMs, offering a tangible solution to the challenges of fluctuating performance and reliability faced by these models. The explicit, structured, and semantically-defined data that knowledge graphs organize are vital for leveraging LLMs to their fullest potential:
- Accuracy: By integrating knowledge graphs, LLMs can tap into a well-organized repository of explicitly-defined, contextual information, significantly enhancing their accuracy and consistency.
- Reliability: The structured nature of knowledge graphs ensures that LLMs have a reliable reference point, reducing the likelihood of generating incorrect or inconsistent responses.
Even further, knowledge graphs help prioritize what’s relevant and important.
Andrew Nyguen suggests in his argument for “data-centric AI” that smaller sets of high quality data are far superior for model training and deployment. While today’s Large Language Models are trained on vast, general data, enterprise AI will instead succeed with this small data approach. Knowledge graphs can serve this “small data” approach through interconnecting across various domains and providing context-rich, targeted information that enhances model understanding and decision-making.
Knowledge Graphs Don’t Just Save LLMs; They Supercharge Them.
It’s not that LLMs are failing. They are performing what they were engineered to do; generating probabilistic outputs based on statistical correlations. LLMs just need contextual grounding. If LLMS were unleashed on well-defined, well-structured, and well-governed data, their accuracy and reliability would remain very high at scale and over time.
A paper published in IEEE represents the synergistic relationship between Knowledge Graphs and LLMs, pointing to how each technology compliments the other. Where LLMs lack contextual grounding through implicit knowledge, knowledge graphs provide structured truth. And where knowledge graphs might lack completeness and generalized knowledge, LLMs help fill that gap.
Businesses aiming to truly build effective AI should prioritize structured data management and governance as their strategy and should appoint knowledge graphs as the vehicle to deliver and maintain these capabilities.
Thanks for reading!
Fluree offers a full suite of semantic data management products to build, maintain, leverage and share enterprise knowledge. Learn more about our comprehensive knowledge graph solutions and book a call to speak with an expert here. Or, dive into more information about our product suite below:
- Fluree Core - Semantic Graph Database with Built-In Security and Digital Trust
- Fluree ITM - Intelligent Taxonomy and Ontology Manager
- Fluree Sense - Semantic Pipeline to Transform Legacy Structured Data to Knowledge Graphs
- Fluree CAM- Intelligent Content Auto-Tagging for Digital Media Assets
*Image Inspiration Credit: LLMs & Knowledge Graphs, Medium
Stay in the loop
Weekly insights on enterprise AI, knowledge graphs, and data intelligence.