How Linked Data Can Help Improve LLM Accuracy and Effectiveness
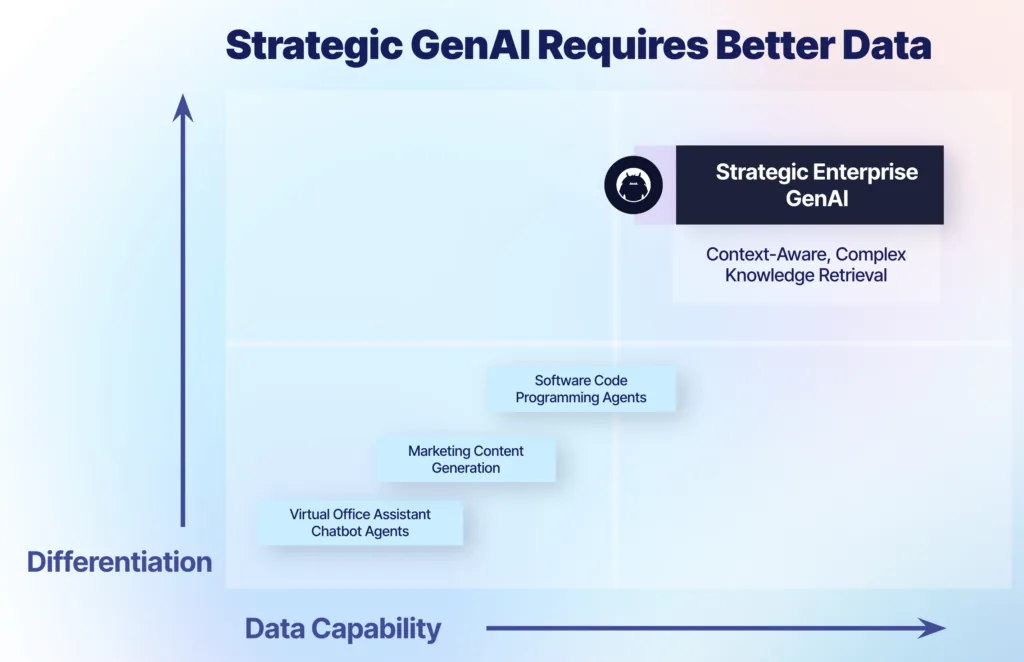
Large Language Models continue to evolve, and organizations are trying to move from the low-hanging fruit use cases (blog post generation, customer service bots) to more complex, specialized use cases (knowledge co-pilots, decisioning agents).
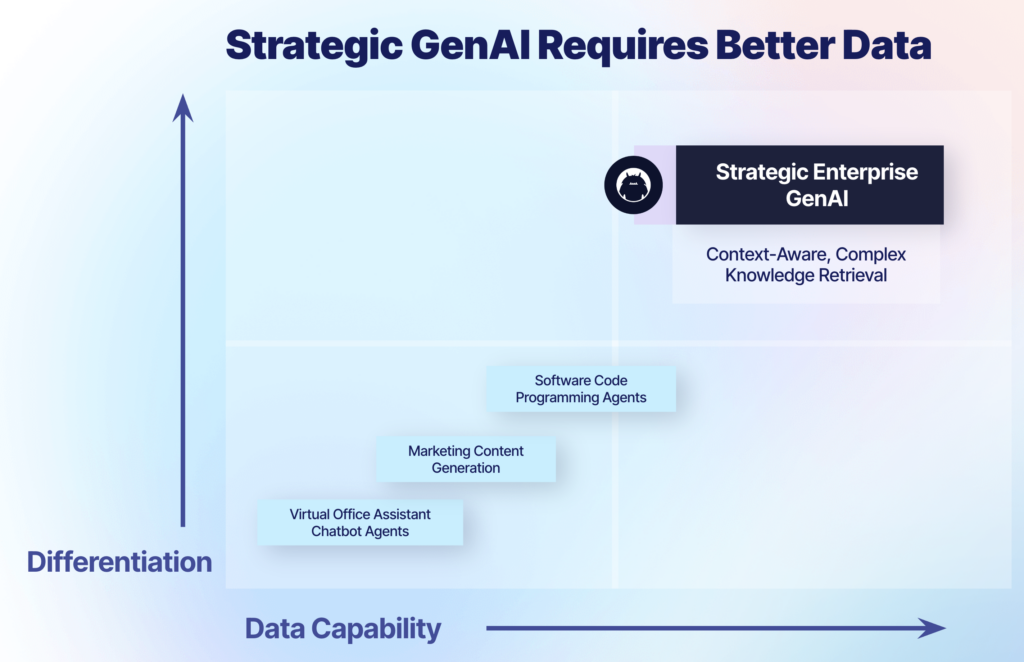
To support these more sophisticated GenAI use cases, we need access to better enterprise data. There are a few patterns that have emerged to support specialized information retrieval, but all of them must tackle a deep-rooted problem that has existed far before the age of Chat-GPT: data silos.
Linked Data has been around for decades – largely to help the internet of URLs connect web pages together under global concepts for better search engine experiences (see schema.org).
By connecting disparate data sources through standardized frameworks, Linked Data allows information to be more easily accessed, shared, and understood. Now, as organizations push the boundaries of what LLMs can do, Linked Data is taking center stage again, offering a way to unify fragmented enterprise knowledge and provide the high-quality, interconnected data GenAI needs. In this article, we’ll explore how Linked Data can help bridge the gap between siloed data and the advanced, decision-making capabilities organizations are striving to achieve with their AI initiatives.
Machine Readability: The Foundation of LLM Accuracy
At the heart of LLMs’ ability to generate coherent and accurate information is machine readability—the ease with which AI models can process and interpret data. Linked Data standards are designed to ensure that data is structured in a way that machines can understand, making them a perfect fit for improving LLM performance.
Linked Data formats like RDF use triples—subject, predicate, object—to describe relationships between pieces of information. This structured approach enables LLMs to “read” the data more effectively, reducing ambiguity and improving the accuracy of the model’s output. When an LLM pulls information from a knowledge graph based on Linked Data, it can leverage these relationships to generate more precise answers, especially in complex or highly specialized queries.
For example, in a pharmaceutical context, Linked Data can help an LLM accurately connect information between drugs, clinical trials, and diseases, ensuring that the AI produces scientifically sound and context-aware outputs. Without the structured relationships provided by Linked Data standards, LLMs would struggle to make these crucial connections, leading to less accurate or incomplete responses.
Enhancing Data Connectivity for LLMs with Linked Data
Another major benefit of Linked Data standards is how they enable better data connectivity. In traditional data structures, information is often siloed, making it difficult for AI models to retrieve the most relevant data. However, Linked Data standards allow different datasets to be connected across platforms, creating a unified ecosystem of information.
When LLMs are trained on this interconnected data, their ability to retrieve the right information improves significantly. Linked Data standards like SPARQL enable precise querying, meaning LLMs can pull from specific data points within a knowledge graph that are directly relevant to the user’s question. This increased precision enhances both the retrieval and generation capabilities of the LLM, resulting in more accurate and effective outputs.
For instance, when querying financial data, an LLM can use Linked Data standards to link transactional data with market analysis, providing predictions based on a well-connected, comprehensive dataset. This capacity to connect and understand data relationships helps LLMs generate more robust insights, improving their overall effectiveness.
Ontologies and Their Role in LLM Effectiveness
When integrating multiple data sets together, we need to apply a global blueprint of terms and concepts germain to the business across the data environment. This allows organizations to apply standards to data and metadata, define global relationships, and ultimately reduce errors, inconsistencies, and duplication
Ontologies—formal representations of a set of concepts and their relationships within a domain—are another key component of Linked Data standards that boost LLM performance. By defining the relationships between concepts in a structured way, ontologies help LLMs better understand the context of the data they’re processing.
Providing your LLM with data modeled against a global ontology is like giving it not just a direction, but a detailed map and compass to follow precise, step-by-step instructions.
Read more about ontologies here.
Because LLMs thrive on understanding context, the use of ontologies dramatically increases their ability to provide accurate responses. Linked Data standards like OWL, which support the creation of rich ontologies, are essential for making sure that LLMs aren’t just regurgitating information but rather generating insightful, context-aware responses. This structure allows LLMs to better interpret data and generate outputs that reflect the nuanced relationships within the field.
Linked Data Standards for Enhanced LLM Retrieval-Augmented Generation (RAG)
In Retrieval-Augmented Generation (RAG), Linked Data standards can play a transformative role in improving accuracy. RAG models combine the retrieval of relevant data with generative capabilities to provide users with well-informed and contextually relevant responses.
The precision of data retrieval in RAG depends heavily on the quality of the data connections and structure. Linked Data standards ensure that these connections are well-defined and machine-readable, allowing RAG models to pull more accurate information from various data sources. By improving the data that RAG models have access to, Linked Data enhances both the retrieval and generation aspects of the process, leading to higher-quality results.
For example, in regulatory compliance for pharmaceuticals, RAG models using Linked Data standards can retrieve data on clinical trials, regulatory guidelines, and drug safety records. With this precise, interconnected data, the LLM can then generate compliance reports that are not only accurate but also comprehensive, reducing the risk of error in critical decision-making processes.
Read more about RAG here.
Thanks for Reading!
Fluree offers a full suite of semantic data management products to build, maintain, leverage and share enterprise knowledge. Learn more about our comprehensive knowledge graph solutions or book a call to speak with an expert here. Or, dive into more information about our product suite below:
- Fluree Core – Semantic Graph Database with Built-In Security and Digital Trust
- Fluree ITM – Intelligent Taxonomy and Ontology Manager
- Fluree Sense– Semantic Pipeline to Transform Legacy Structured Data to Knowledge Graphs
- Fluree CAM– Intelligent Content Auto-Tagging for Digital Media Assets
Master Enterprise AI with Semantic GraphRAG
Unlock the full potential of your enterprise data with Fluree’s comprehensive guide to semantic GraphRAG. Learn how to build intelligent, context-aware AI systems that deliver accurate, explainable results.
Unlock the Power of Semantic AI
Join our expert-led webinar to discover how semantic AI transforms enterprise data management. See real-world examples and learn implementation strategies that drive business value.
Experience Fluree in Action
Ready to see how Fluree’s semantic graph database can transform your data architecture? Get hands-on experience with our platform and discover the power of connected, intelligent data.
Stay in the loop
Weekly insights on enterprise AI, knowledge graphs, and data intelligence.