
Welcome to part 5 of our data-centric architecture series! We’ve covered the basics of the data-centric architecture - Digital Trust, Security, Semantic Interoperability, and Time. All of these components weave together for a truly powerful data-centric architecture - one that enables agile data collaboration across boundaries, reduces attack surfaces, destroys data silos, and delivers high-value data to data stakeholders with precision and accuracy.
This final chapter in this series will focus on data sharing and data collaboration. With Fluree, we’ve already built an incredibly powerful data platform - now let’s give our stakeholders the access they need, at the velocity they require, with the quality they deserve. Data sharing can take many forms (reciprocal or one-directional) - and operate within a variety of contexts (sharing analytics with partners, collaborating on labeled data sets, providing aggregate data to a client, or simply gathering an internal data catalog for a more efficient master data management strategy). Whatever the context, data sharing requires a scalable data-centric architecture. Let’s dive in:
What is Data Sharing?
Let’s break down a few key data-sharing patterns and thematic use cases within each:
Data Virtualization (Many Data Sources > One Consumer)
A simple stepping stone in data collaboration that most enterprises have implemented in various ways, data virtualization involves federating data from multiple disparate sources. This simple but powerful pattern moves us away from replicating or physically moving data in order to access it. A great example of data virtualization in action would be a data catalog that enables fast data access and self-service data analytics for anyone within an organization.
Data-as-a-Service (One Data Source > Many Consumers)
Data-as-Service (DaaS) involves preparing and delivering curated data sets to end-users. An excellent example of DaaS in action would be a data brokerage or data marketplace in which a data aggregator distributes data to buyers. Data-as-a-service paves the way for organizations to look beyond traditional sources of data and into the benefits of external, third-party information.
Data Exchange (Data Sources <> Data Consumers)
A Data exchange involves the bidirectional flow of information across participating organizations. Data exchanges can support many<>many reciprocal models where multiple data sources and multiple data consumers collaborate in a complex and hybrid environment. Examples of data exchanges might include data collaboration across supply chain partners or reciprocal data analytics sharing across an industry consortium.
Why Share Data?
Our introduction to data-centricity mentions how data has become more of a versatile and valuable asset rather than just a row in a relational database. And this value should be shared. Modern data ebbs and flows across various applications, workflows, and even organizations. This increase in digital collaboration is becoming a necessity to remain competitive as organizations are finding bottom-line value in data-sharing ecosystems.
Capgemini reports that "the potential financial benefits of data sharing ecosystems can reach 9% of annual revenue of an organization over the next five years." These benefits take the form of improving data analytics strategies and integrating a highly data-driven approach into operations - with real-world impact. Capgemini’s study found that organizations that participated in data sharing ecosystems had improved customer satisfaction by 15%, improved workflow efficiency by 14%, and reduced costs by 11%.
Data sharing bolsters data’s inherent value, which by nature improves the quality of any organizational process that involves shared data.
Making the change:** **From data hoarding to data collaboration
Before we get to the technology toolbelt required to build data-sharing ecosystems, let’s chat culture. It’s well known that the great plague of the data silo is not just the result of vendor lock-in or outdated technology. Mindset is also a powerful factor in the status quo culture of information withholding. Data and Analytics leaders, departmental units, and organizations as a whole have become steeped in a data-hoarding mindset over the last decades.
But times are changing - The US Department of Defense, one of the largest data organizations in the world, announced this year a shift from sharing data on a "Need to Know" basis to a "Responsibility to Provide" culture. The DOD recognizes that the power of data in the hands of many outweighs the perceived risks associated with data collaboration. The private sector is following suit - 48% of organizations plan to launch new data-sharing ecosystems in the near future, among those, 84% intend to do so within the next three years (source).
Data-Centric Architectures Power Data Sharing Ecosystems
Alongside the philosophical shift to becoming a data-sharing organization, there is also a technology shift - from application-centric to data-centric.
Let’s take a look at some top "issues" that will arise for organizations building data-sharing platforms, and how Data-Centric platforms like Fluree solves each one right from the start (click on each for a complete description).
Compliance: How do we share data without risking violation of a data compliance regulation?
Simple or complex data sharing could result in a violation of GDPR or a similar privacy act. Just this month, Plaid settled a $58 million class-action lawsuit over claims that the fintech firm passed on personal banking data to third-party firms without user consent.
Data governance and data privacy are evolving landscapes, and the risks associated are compounded in a data-sharing environment.
Fluree’s Smart Function capabilities allow for the creation, management, and enforcement of granular data policies for an airtight approach to data-centric compliance.
Read more: Data-Centric Security
Digital Trust: How do we trust and authenticate data sources?
Integrating third-party data into your critical operations opens risk. For one, you must account for the possibility of malicious data poisoning (manipulation of information with the intent to harm). For another, you need to be able to validate data came from a certified, legitimate source. We need cryptographic methods to prove sources of data as well as the history of CRUD operations to data.
Gartner predicts that through 2023, organizations that can instill digital trust will be able to participate in 50% more ecosystems, expanding revenue-generation opportunities.
Fluree integrates digital trust into data using a cryptographically secured immutable ledger. This approach allows us to categorically prove time, source, and history for each and every datum in the system.
Read more: Data-Centric Trust
Security and Governance: How do we manage access control and other permissions, and enforce them dynamically along the data supply chain?
Data sharing doesn’t mean everyone has access to everything by default - so how do we facilitate quick and complex data collaboration that is also secure? How can we dynamically update permissions to reflect changing business contexts? Harmonizing data policies — especially complex and context-specific ones - across a hybrid environment could become difficult at scale.
Fluree’s SmartFunctions allow the enforcement of arbitrarily complex data security policies and data shape validation at the data layer and support data-centric security initiatives such as cell-level security, attribute-based access control (ABAC) models, and granular permissioning logic.
Read more: Data-Centric Security
Accessibility: How do we ensure that data is discoverable and available for all data participants?
What’s the point of sharing data if it can’t be readily discovered and accessed?
Data must be formatted in a way that it can be easily discoverable using a strong metadata strategy. In order to accomplish this at a broad scale, data ecosystems should adhere to the F.A.I.R. principles of data management (Findable, Accessible, Interoperable, and Reusable).
Fluree’s semantic data platform can autogenerate FAIR data, enforce ongoing compliance to FAIR data standards with governance-as-code, and power consumers of FAIR data for read/write applications.
Read more: Making Data FAIR with Fluree
Interoperability: How do we make data interoperable across data sources and consumers?
Both humans and machines must be able to comprehend data under a common semantic understanding - otherwise, the value of data exchange is severely diminished. Common data formatting with semantic vocabularies (ontologies) allows data consumers to exchange data with meaning.
As a semantic RDF graph database, organizations building on Fluree’s data platform gain the instant benefit of interoperability with other standards-based systems.
Read more: Semantic Interoperability
Time: How can multiple stakeholders coordinate across data in real-time?
Data ecosystems need to lock in a shared understanding of time in order to efficiently collaborate and exchange information. For example, multiple systems (or humans) leveraging a mutual data source need a trusted, consistent view of information without the possibility that it could have served up older or newer versions to different consumers as queries concurrently hit.
Fluree’s temporal immutable ledger provides timestamps as a metadata characteristic. This ability to have a full history of data versions allows microservices architectures or data scientists to “lock in” a specific time for reliable query results. This capability becomes increasingly valuable in data applications where real-time data drives decisions or operations across an ecosystem.
Read more: Data-Centric Time Delivery at Scale: How do we deliver data with agility in a hybrid environment?
Data stakeholders will need real-time access to the most up-to-date information. We’ll need to maximize cloud uptime to deliver data at the highest velocity possible to end-users without breaking the bank.
Fluree’s architecture was built for data scale. Fluree’s distributed ledger maintains all-state for the platform, freeing the graph database to run fully stateless as a scalable data delivery network.
Fluree’s database engine runs on the JVM or JavaScript and is capable of operating in-memory; it can scale dynamically and runs easily in containers or even as an in-browser web worker.
Learn more: Data-Delivery at Scale with Fluree (Video)
Multi-Modal Access: How do we deliver heterogeneous data to stakeholders without orchestrating multiple service layers?
Complex data ecosystems will involve the exchange of multiple different kinds of data, as well as different preferences in how participants query that data. Instead of building out various interfaces to service each kind of query workflow, a multi-modal database provides a unified and integrated platform for data retrieval. Multi-modal data access allows data consumers to query data in the language of their choice and in the shape and format of their particular needs.
Multi-modal access lets developers spend less time on the integration points between front and back ends, and more time building data-centric applications.
Fluree supports multi-modal query — as a native JSON database, Fluree can retrieve data in JSON (FlureeQL), SPARQL, and SQL. External consumption is made easy with these standards-based interfaces. Learn more about Fluree query patterns here.
Building Data-Centric Ecosystems with Fluree
Data-centricity and data sharing go hand-in-hand. It’s not enough to be "data-driven" - data-sharing platforms that truly scale must be "data-centric." We could theoretically address all of the above issues individually with different bandaid technologies - but a data-centric architecture approach to building a data-sharing ecosystem is far more scalable and effective. The foundation of Fluee’s data-centric architecture is predicated on the need for flexible, trusted, and secure data sharing at any scale and within any context.
Fluree enables secure and direct data sharing for any kind of data ecosystem.
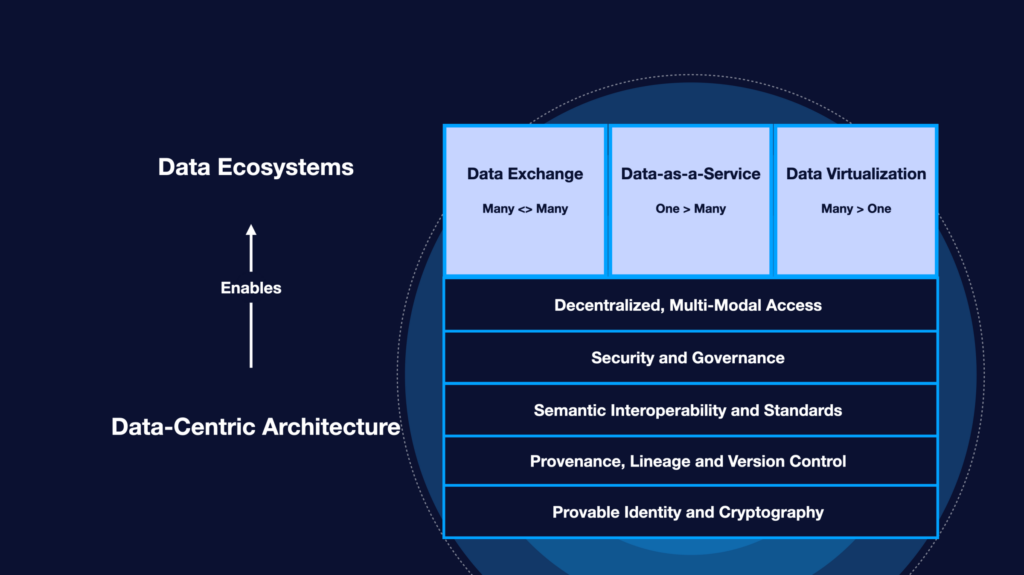
In summary, Fluree enables data sharing ecosystems using the following characteristics:
Conclusion
You’ve reached the final chapter in our data-centric architecture series - thanks for following along. As you may have noticed, our first four data-centric capabilities (trust, security, interoperability, and time) all build on one another to ultimately enable our fifth capability - data sharing. Once these layers are built into the foundation of data architectures, we can accelerate transformation up and down the data value chain. Ecosystems can become more agile around data. Ecosystems can expand to serve more data stakeholders. Ecosystems can connect to other ecosystems. All in the name of secure and efficient data sharing.
Data sharing and collaboration are at the heart of Fluree’s core use cases - including large organizations like the US Air Force, collective projects like the Blockchain Innovation Challenge hosted by the Department of Education, and dozens of startups innovating in financial services, identity, supply chain, and HR. Get started with Fluree here.
Stay in the loop
Weekly insights on enterprise AI, knowledge graphs, and data intelligence.