Building Corporate Memory for Enterprise LLMs

Organizations today are likely hitting their peak of inflated expectations after a few rounds of LLM Proof of Concepts. While new and powerful models like GPT-4o mini and Claude 3.5 Sonnet hit the market to provide greater intelligence at a lower cost, organizations are still hitting the same barriers when trying to scale enterprise LLMs to production:
- Accuracy
- Relevance
- Context
These barriers – among others – can be generally attributed to how enterprise data and content are organized, managed, and accessed. Mckinsey recently stated that “Managing data remains a top barrier to value creation from GenAI.” Let’s get more specific: GenAI that isn’t grounded in contextual, trusted, and real-time data is never leaving the proof-of-concept bucket.
In order for organizations to truly deploy LLM applications that are context-aware and hallucination-proof, they must build and maintain their corporate memory.
What is Corporate Memory?
Corporate memory refers to the collective experience, information, and knowledge accumulated by an organization over time.
Corporate memory is more than just your operational or analytical data; it’s the essence of your organization’s history and positioning, key processes, business strategies, metrics, and lessons learned that have shaped your journey. In other words, it’s enterprise context.
Corporate Memory lives in unstructured content like PDFs, presentations, FAQs and email documents, as well as in structured data stored in databases, SaaS applications, and data lakes. More importantly, it resides in the minds of your subject matter experts (SMEs). Wherever your corporate memory lives, the ability to bring it together into a singular “corporate brain” is the key to building context-aware information retrieval for Generative AI.
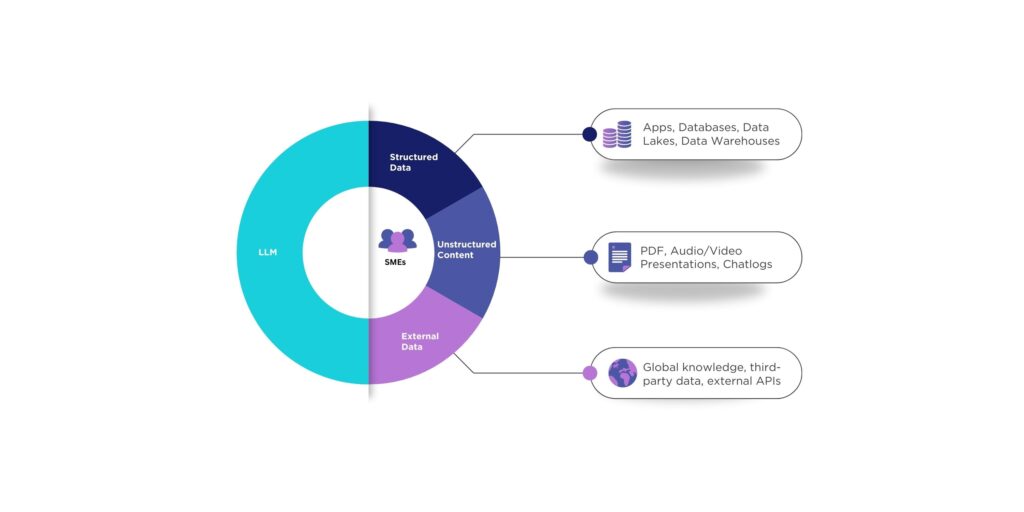
But oftentimes, organizations have a lack of good corporate memory – they have what we might call corporate amnesia.
What is Corporate Amnesia?
Corporate Amnesia occurs when an organization has no easy, repeatable access to the knowledge it generates or captures. The organization in question might have some semblance of corporate memory, but it is spread out in artifacts that are held in isolated information systems.
Symptoms of corporate amnesia might look like the following:
Corporate Amnesia might look like a banker trying to piece together a full customer profile from duplicate CRM records, an insurance salesman sifting through thousands of PDFs to find the right policy group for a client, a customer service representative frantically searching through internal FAQ documents to find the answer to a rare question, or the risk department at a financial institution struggling to identify patterns in historical data because key insights are buried in outdated spreadsheets and isolated databases.
If humans are struggling with getting access to relevant, real-time knowledge from across their organization, LLMs can’t be doing too much better.
LLMs Don’t Have Access to Your Corporate Memory – Yet.
A lack of available, accessible, and well-documented institutional knowledge might be the result of the “big data” boom in the early 2000s: Lots of data, stored in different formats, living across isolated, separate systems. These systems and applications were not built for re-usability beyond basic query/retrieval.
Today, organizations are responding to these issues with a few bandaids: ETL, data lakes, and manual data cleansing in order to get information from systems into a RAG pipeline. But these are neither sustainable nor scalable methods if LLMs need continuous, grounded access to information in real-time.
Why Semantics is the Key First Step
A fundamental challenge in bringing any kind of disparate information together will be in aligning concepts. What a sales report located in a CRM might call “customer,” an invoice located in a finance ERP system might call “client.” If we were to simply dump information together in a massive data lake, we wouldn’t really have integrated data – we’d just have a mess to clean up before it can be of any use.
Last year, we wrote a fairly extensive piece on Semantic Interoperability – the ability for disparate systems to “speak the same language.” Implementing a semantic layer can serve as a universal framework to define the concepts and relationships across your data assets. This is a key step in moving towards building corporate memory for LLMs - understanding and representing the semantic meaning behind data allows information to be linked together and retrieved in a context-aware manner.
Semantics gives us a few key advantages in bringing information together:
-
Established relationships across data assets - Semantics enables the explicit definition and management of relationships between data entities through ontologies. By inferring and maintaining these relationships, it allows for more accurate and meaningful connections across disparate data assets. This not only enhances data integration but also ensures that queries and information retrieval are contextually accurate, leveraging the full breadth of interconnected knowledge.
-
Increased Accuracy and Precision - In working with customers as well as our own internal experiments, we’ve found that RAG against a semantic knowledge graph increased baseline response accuracy by up to 4x over a traditional relational database. GraphRAG has gained momentum as the best step towards hallucination-free information retrieval.
-
Contextual Understanding Beyond Exact Terms Prompts – or natural language queries written by the user – don’t have to use the perfect, explicit terms located in the various schemas of the datasets containing key information. Regardless of phrasing used, we can tell the machine what we are looking for with semantic meaning as added context to both the prompt and the available data. This is far superior to vector similarity searches because instead of a probabilistic outcome, we achieve precise, contextually relevant results that align with the true intent of the query.
A semantic layer in your data architecture serves as a bridge between disparate data sources and LLMs, ensuring that your models have access to the right information at the right time. By applying semantic technologies such as knowledge graphs, ontologies, and metadata management, organizations can unify their data into a coherent, machine-readable format. This not only enhances the accuracy and relevance of the information retrieved but also reduces the chances of AI hallucinations, where the model generates responses based on incorrect or incomplete data.
Injecting Corporate Memory into LLMs
We’ve found that the best possible data management platform for creating and managing “corporate memory” involves the following components:
- Data - We must surface information held in structured and unstructured systems
- Ontologies - We must classify and interconnect information against a universal set of concepts
- Security - We must use the ontology to define key policy frameworks. We’ll discuss security in our last section
Combining the above elements into a semantic knowledge graph layer allows us to dynamically tap into the collective knowledge of the organization.
This approach ensures that all relevant data, regardless of its original format or location, is accessible and usable by LLMs. Because we’ve made use of a universal ontology, we can classify every piece of data/content at the source of ingestion into the knowledge graph.
The semantic knowledge graph acts as a living repository of corporate memory, continuously evolving as new data is ingested and existing information is refined. By integrating this semantic layer into your data architecture, you empower your AI models to make informed decisions, improve operational efficiency, and maintain consistency across all levels of your organization. This approach not only maximizes the utility of your data but also ensures that your AI-driven applications remain reliable and contextually aware.
To truly integrate corporate memory into LLMs, organizations must go beyond simply moving their stored data into a single lake or warehouse. They need to create a dynamic, living corporate memory that is continuously updated and enriched with new knowledge.
The Future of Enterprise LLMs with Corporate Memory
The majority of LLM applications that are deployed today are useful tools that help automate a simple process – such as generating blog posts for marketing, managing call center chat interactions, summarizing documents, drafting emails, and even providing basic customer support.
But we can start to see the true potential of Generative AI just around the corner: complex knowledge retrieval that can enhance critical components of our business processes; use cases that involve both a deep understanding of the business and true real-time access to available knowledge held across multiple systems.
The ability to manage and utilize corporate memory effectively will become a critical differentiator for organizations to achieve these advanced GenAI applications. Thanks for Reading!
Fluree offers a full suite of semantic data management products to build, maintain, leverage and share enterprise knowledge. Learn more about our comprehensive knowledge graph solutions or book a call to speak with an expert here. Or, dive into more information about our product suite below:
- Fluree Core – Semantic Graph Database with Built-In Security and Digital Trust
- Fluree ITM – Intelligent Taxonomy and Ontology Manager
- Fluree Sense– Semantic Pipeline to Transform Legacy Structured Data to Knowledge Graphs
- Fluree CAM– Intelligent Content Auto-Tagging for Digital Media Assets
Master Enterprise AI with Semantic GraphRAG
Unlock the full potential of your enterprise data with Fluree’s comprehensive guide to semantic GraphRAG. Learn how to build intelligent, context-aware AI systems that deliver accurate, explainable results.
Unlock the Power of Semantic AI
Join our expert-led webinar to discover how semantic AI transforms enterprise data management. See real-world examples and learn implementation strategies that drive business value.
Experience Fluree in Action
Ready to see how Fluree’s semantic graph database can transform your data architecture? Get hands-on experience with our platform and discover the power of connected, intelligent data.
Stay in the loop
Weekly insights on enterprise AI, knowledge graphs, and data intelligence.