Fluree AI is hereFluree AI is here — the hosted Fluree platform, built on FlureeDB. Get started free
The Unified
Intelligence
Platform
Throw everything at Fluree.
We connect the dots automatically,
and give your AI a place it can actually trust.


Trusted by










Real results across
industries we serve.
USE CASE Financial Services

10,000+
documents extracted
Driving Just-in-Time Decision Intelligence
A financial services leader used Fluree to automate tagging, improve discovery, and grow a data portal into a more trusted intelligence destination.
“ By integrating Fluree into its content supply chain, the client eliminated error-prone tagging, expanded its knowledge base tenfold, and regained the trust of portal users consuming the data.”
Source: financial services data portal case study



Put your data to work
One place for your data and context — infinite interfaces on top.

10:30 AM
Dana Whitfield
SVP, SALES
“Flag any account with revenue at risk from billing or CRM data gaps — and stage the fixes for my approval.”
Fluree AI
10:32 AM
Recalling Memories
list_agents
Inspecting Knowledge · small-billing
Inspecting Knowledge · small-crm
Extracting · accounts with billing gaps
10:33 AM
Dana Whitfield
SVP, SALES
“Now give me a live dashboard of total liquidity and revenue at risk across those accounts.”
Fluree AI
10:34 AM
$48.21M
▲ 2.4%
Query-driven
Permissioned
Traceable
Up to date
Auditable
10:40 AM
Dana Whitfield
SVP, SALES
“Turn that into an app my RevOps team can use to triage at-risk accounts.”
Fluree AI
10:42 AM
At-risk accounts
Northwind Trading
$980K
Atlas Logistics
$760K
Vertex Health
$640K
10:50 AM
Dana Whitfield
SVP, SALES
“Deploy an agent that watches for new revenue risk and acts within policy.”
Fluree AI
Setting up agent now
Your Agent will watch for
Invoice posted
Account updated
Risk flag raised
Then it acts within your policy staging fixes for approval, with every step logged & reversible.
Permissions locked to the user, agents & AI
enforced on every request
Memories are graphs
rich person, space & company context
Finds the right data agents
to carry out the task
Queries across multiple sources
in one connected, verified graph
Structured queries against the graph
return verifiable, data-grounded answers
10:30 AM
Dana Whitfield
SVP, SALES
“Flag any account with revenue at risk from billing or CRM data gaps — and stage the fixes for my approval.”
Fluree AI
10:32 AM
Recalling Memories
Completed
list_agents
Completed
Inspecting Knowledge · small-billing
Completed
Inspecting Knowledge · small-crm
Completed
Extracting · accounts with billing gaps
Completed
Plug in your AI.
Or use ours.
Claude, OpenAI, Gemini, Ollama — any MCP-speaking agent reasons over the same graph. No tools yet?
Run on Fluree AI, built in.
Claude
OpenAI
Gemini
Ollama
Fluree AI
Bring your people
Every question, answer, and action that flows through the system
compounds into shared context making your entire organization more knowledgeable over time.
Dana Whitfield
SVP, Sales
Marcus Lee
VP, Finance
Priya Nair
Head of Data
Sam Ortiz
RevOps
Aisha Khan
Analyst
Tom Reed
Engineering
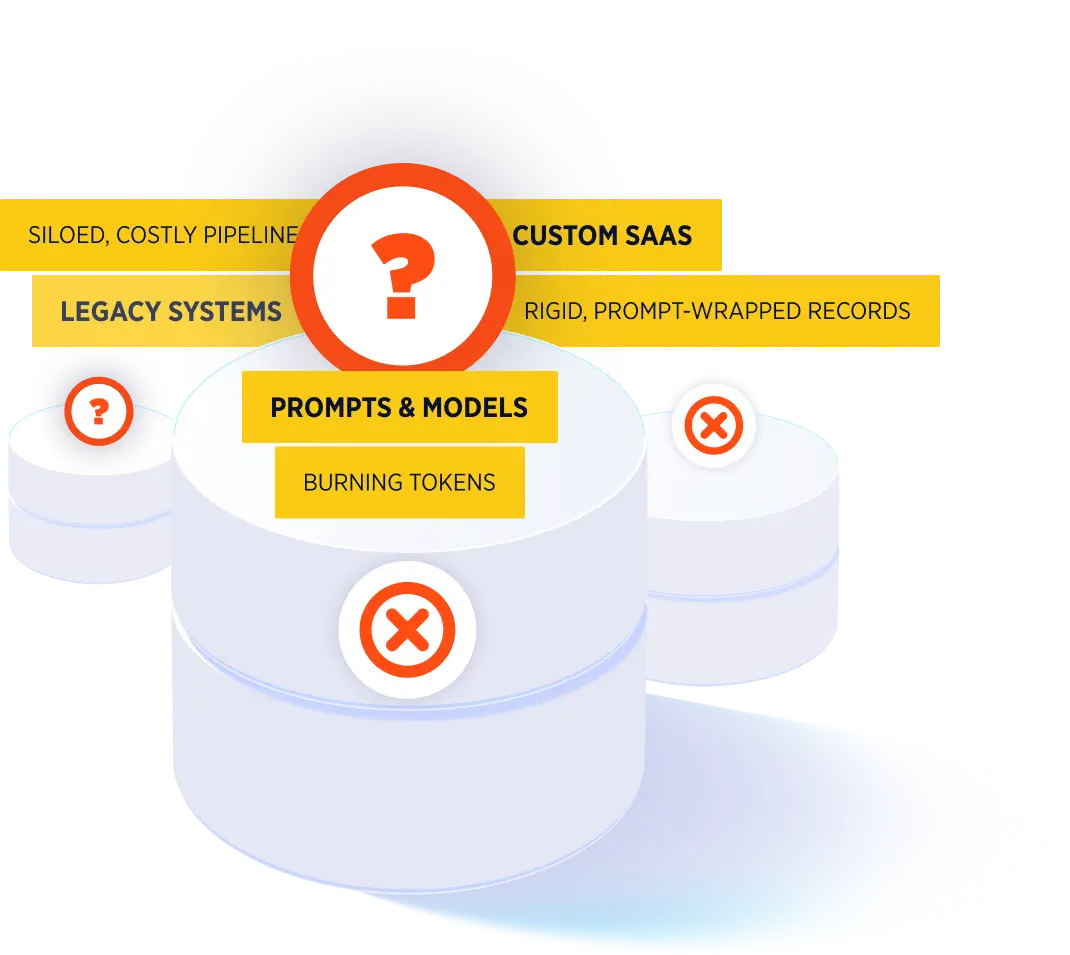
Don’t outsource
your intelligence
Scattered,
expensive context
AI and workflows built in silos — duplicated, costly, and disconnected.
Own and leverage
your intelligence
Future-proof and pluggable — your graph gets sharper with every new source, human, and agent you add.