Context-in-the-Loop: The Architecture for Autonomous AI


A framework for the next generation of enterprise AI agents — and the reason the conversation has shifted from “which model?” to “can this agent safely act inside our business?”

The problem with today’s agent architectures
Enterprise AI has hit a paradox. Models keep getting better. Pilots keep failing. The reason is no longer model capability — it’s that the model is being asked to operate inside a business it doesn’t understand.
The patterns that got us this far are running out of room.
LLM-in-the-loop — the prompt-window pattern — generates plausible text but hallucinates the moment it has to be specific. It doesn’t know what your customer’s balance is, whether a vendor is approved, or whether the policy quoted last month is still in force.
Human-in-the-loop (HITL) improves trust by inserting a reviewer. It works in narrow, low-volume scenarios. It doesn’t scale to the volume leadership is now asking for. Gartner forecasts that more than 40% of agentic AI projects will be canceled by the end of 2027, and the most common cause is exactly this: agents that need a human in the loop for every action aren’t autonomous, they’re a slower form of recommendation.
If every agent action requires a human approval, you don’t have automation. You have a faster recommendation engine.
The conversation is shifting. Chief data officers and platform leaders are no longer asking which model? They’re asking: can this agent safely act inside my business?
That question is the right one. And it has a structural answer.
What data-in-the-loop solves
The first real fix was retrieval. Instead of asking an LLM to recall the world from training data, Retrieval-Augmented Generation (RAG, introduced by Lewis et al. at Meta in 2020) lets the model pull authoritative facts from an external store at query time. Call this pattern data-in-the-loop (DITL).
It works. Hallucination rates drop. Decisions become traceable to a source. Compliance teams can audit what the agent saw and what it said. DITL is the foundation of nearly every credible enterprise AI deployment shipping today.

But the pattern has a ceiling.
DITL answers what is true? It does not answer what matters here?
Why data alone is not enough
A fact, in isolation, is rarely a decision.
Consider a supplier-approval agent. The data layer returns: Vendor X risk score = low. The agent is ready to approve.
Now add the surrounding context:
- Vendor X is tied to a strategic initiative that’s three weeks behind schedule.
- The procurement policy was updated last Tuesday with new tier-2 spending limits.
- The original requester is on PTO; their delegate has different approval authority.
- The last two purchase orders to this vendor were flagged for review by Finance.
The same data — risk score, vendor record, requested amount — leads to a completely different decision once the relationships, policies, history, and current state are visible to the agent.
This is the gap between retrieval and understanding. It shows up everywhere meaningful enterprise decisions get made: customer support, fraud detection, healthcare triage, underwriting, regulatory reporting. The data is correct. The decision still depends on what surrounds the data.
DITL isn’t wrong. DITL is necessary but not sufficient. Real enterprise autonomy requires something more.
Defining Context-in-the-Loop
Context-in-the-Loop (CITL) is an agentic architecture in which AI systems incorporate not only trusted data, but also the relationships, policies, history, goals, and real-time state that determine whether an action is appropriate.
Where DITL grounds the model in facts, CITL grounds it in the operational picture those facts live inside.
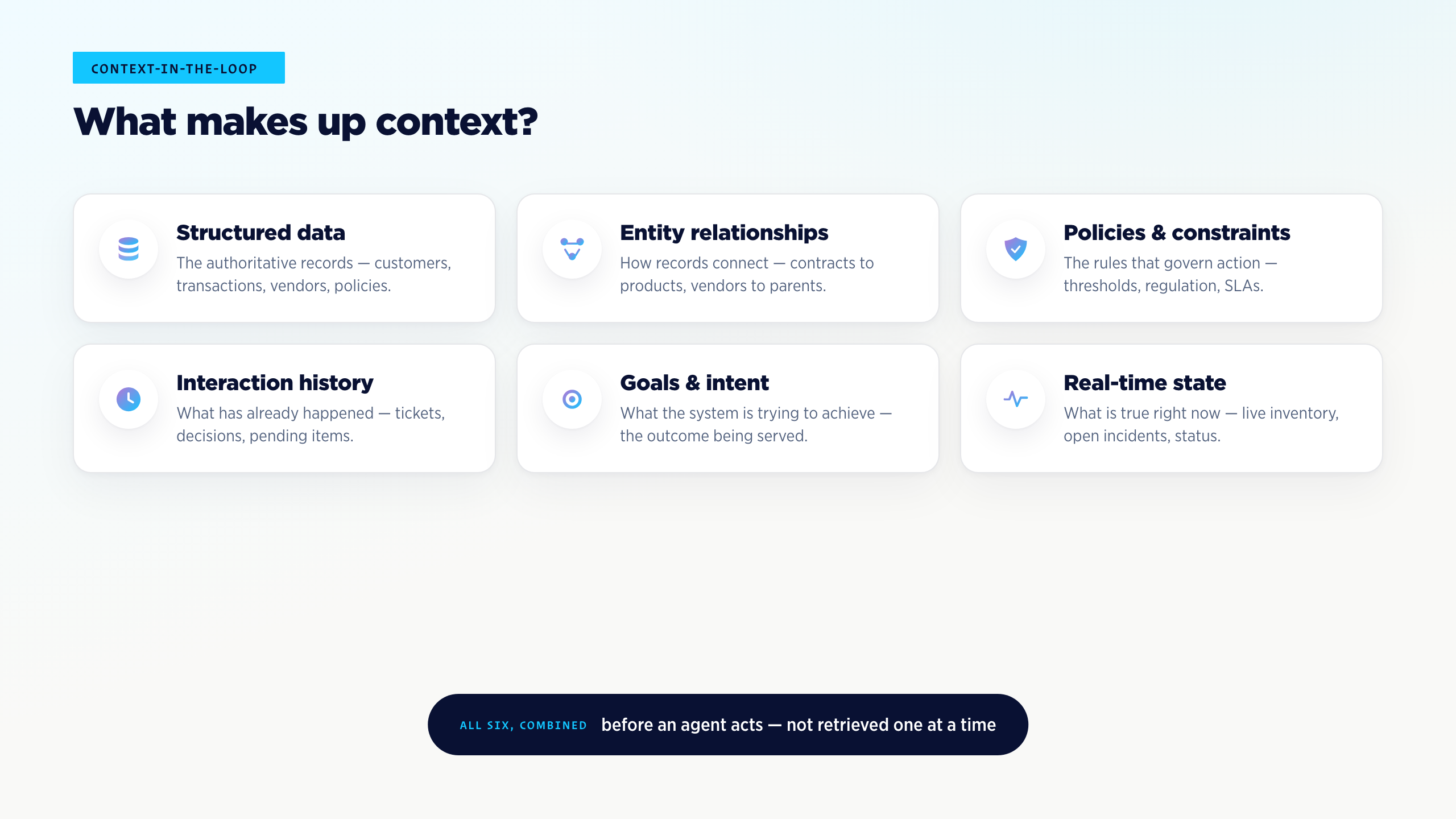
CITL combines six layers of signal:
- Structured data — the authoritative records. Customer profiles, transaction history, vendor records, policy documents. The same trusted facts that ground DITL.
- Entity relationships — how those records connect. Which contracts cover which products. Which employees belong to which cost centers. Which vendors share parent organizations. This is where knowledge graphs earn their place.
- Policies and constraints — the rules that govern action. Approval thresholds, regulatory requirements, internal SLAs, segregation of duties. Treated not as filters layered on top of the model, but as facts the agent retrieves and respects.
- Interaction history — what has already happened. Previous tickets, prior decisions, recent exchanges, pending items. The agent shouldn’t treat every conversation as the first.
- Goals and intent — what the system is trying to achieve. The user’s objective, the workflow’s success criteria, the business outcome being served.
- Real-time state and events — what is true right now. Live inventory. Current account status. Open incidents. The model of the world has to match the world.
A CITL system doesn’t just ask “what does the database say?” It asks “given everything connected to this situation, what’s the right next action?”
A real-world scenario
The shift is easiest to feel in a single example. A customer asks: Where is my order?
| Architecture | Response |
|---|---|
| No grounding (LLM only) | “I don’t have access to your order information.” |
| Data-in-the-loop | “Your order shipped yesterday.” |
| Context-in-the-loop | “Your order shipped yesterday, but the carrier flagged a weather delay in your region. I’ve upgraded the shipment to expedited and applied a service credit since you’ve reached out twice this week. A confirmation will land in your inbox in five minutes.” |
All three responses are technically grounded in truth. Only the last one is operationally useful. The difference isn’t a smarter model — it’s that the third agent could see the shipment, the carrier feed, the customer’s interaction history, the service-credit policy, and the brand standard for delay handling, all at once, all connected.
CITL doesn’t make the agent more eloquent. It makes the agent aware.
Why knowledge graphs matter
The reason CITL has been hard to ship is that most enterprise data layers don’t carry the signal an agent actually needs.
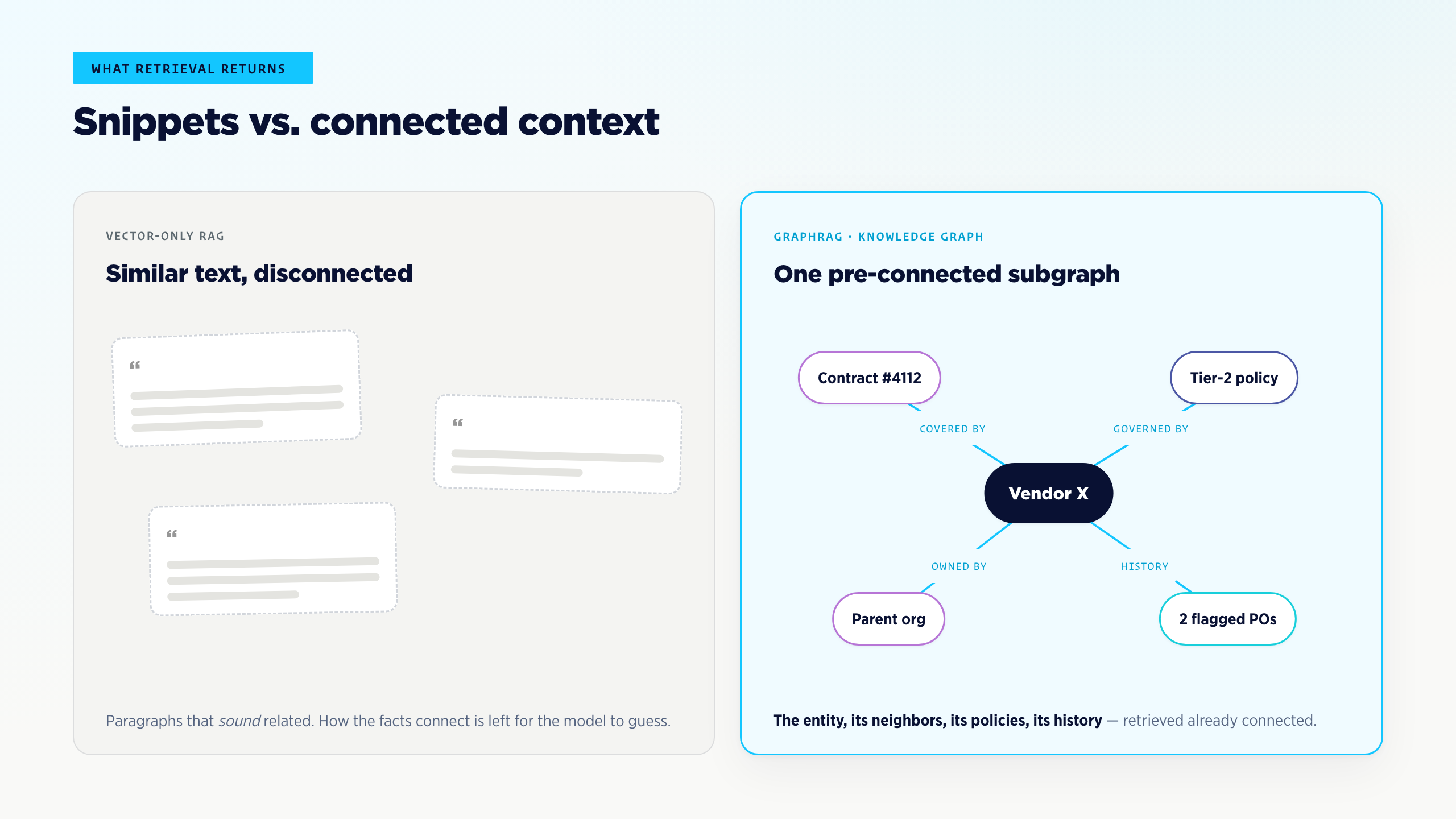
Documents in a vector store give you semantic similarity — useful for finding text that sounds related. They don’t give you connections. A vector search can return a paragraph about Vendor X and a paragraph about a procurement policy update; it can’t tell you that those two facts are linked through a specific contract, an approval chain, and a delegated authority.
That is what a knowledge graph is for.
A graph is not valuable because it stores data. It is valuable because it stores contextual relationships: explicit, queryable, governable connections between the entities your business actually cares about.
This is also why GraphRAG is more than a marketing variant of RAG. Where vector-only RAG retrieves text snippets, GraphRAG retrieves pre-connected context — the entity, its neighbors, the policies that govern it, the history attached to it. The model gets the operational picture instead of stitching it back together from prose.
When the underlying graph is governed at the data layer — with policy, provenance, and access control as properties of the data itself — CITL becomes practical. The agent can be trusted to act because the substrate makes safe action possible. We expand on this maturity model in The Six Levels of the Autonomous Enterprise.
The enterprise architecture pattern
In practice, a CITL system has four parts.
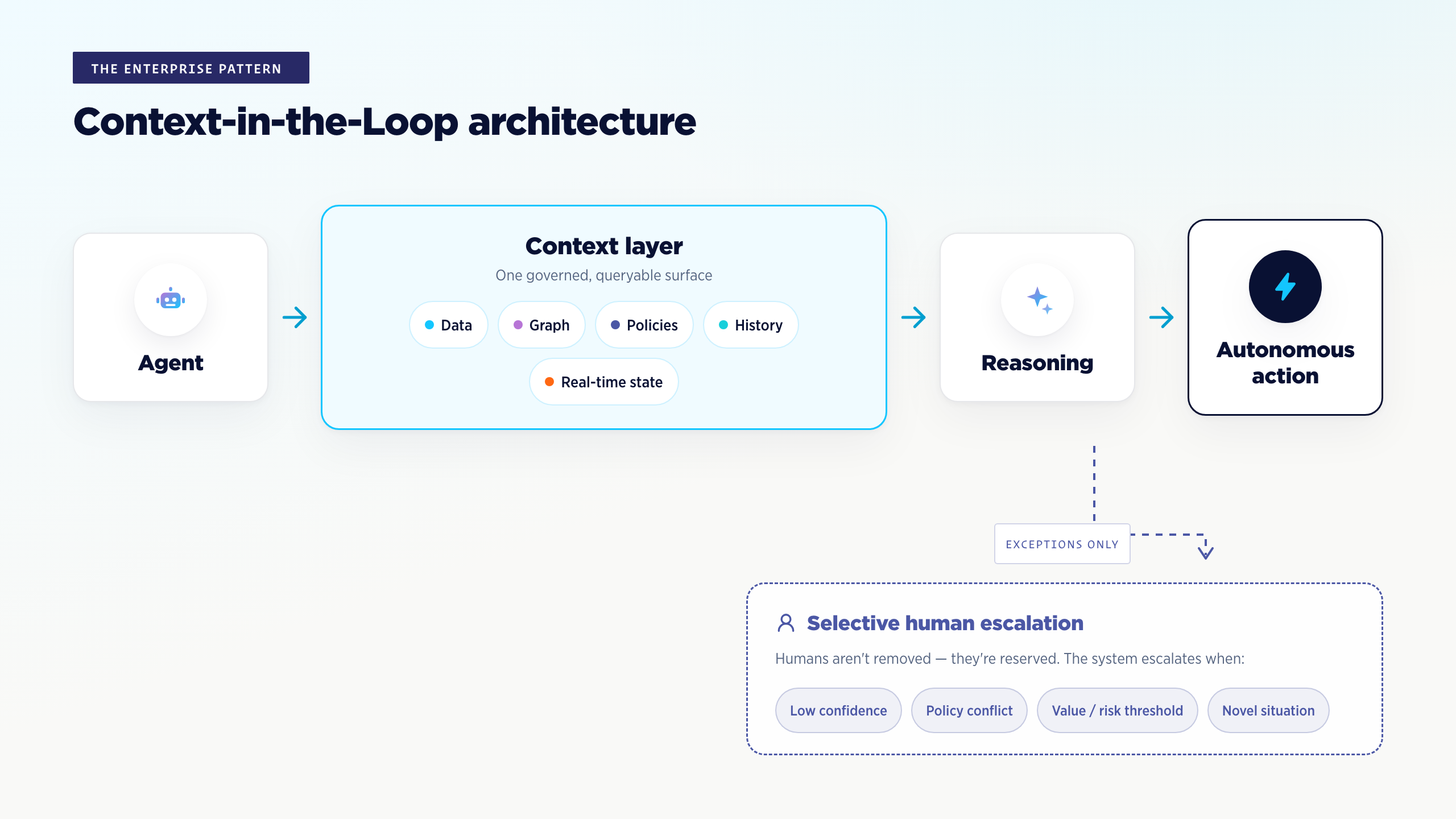
- Context layer — a unified, governed substrate that exposes data, relationships, policies, history, goals, and state as a single queryable surface. This is the semantic layer that sits between your raw systems and any application or agent that consumes them.
- Reasoning — an LLM, or a coordinated agent mesh, operating against that context surface. The model’s job shrinks: it doesn’t have to guess, it has to interpret.
- Action layer — the writes the agent is authorized to make, enforced by the same data-layer policy that governs reads. Security is a property of the data, not a filter in front of the model.
- Selective human-in-the-loop — humans are not removed. They are reserved. The system escalates to a person only when:
- confidence falls below a defined threshold,
- policies conflict or require interpretation,
- the action crosses a value or risk boundary, or
- the situation is genuinely novel and not represented in the substrate.
This is the inversion that matters. In traditional HITL, humans approve every action and review the exceptions afterward. In CITL, the substrate handles every action and humans review only the exceptions. The same governance bar — applied with different leverage.
The NIST AI Risk Management Framework refers to this pattern by another name: layered control. Context-in-the-loop is the implementation that makes layered control operational without strangling throughput.
What this means for the next two years of AI investment
Three implications for leaders deciding where to spend.
First, stop evaluating models in isolation. A frontier-tier model running on a vector store with no contextual structure will be outperformed in production by a mid-tier model running on a governed knowledge graph. The model is not the bottleneck. The substrate is.
Second, treat context as infrastructure, not prompt engineering. “More tokens in the prompt” is not context. Context is the connected, governed, policy-aware operational picture an agent retrieves at query time. It belongs in the data layer, not the application layer.
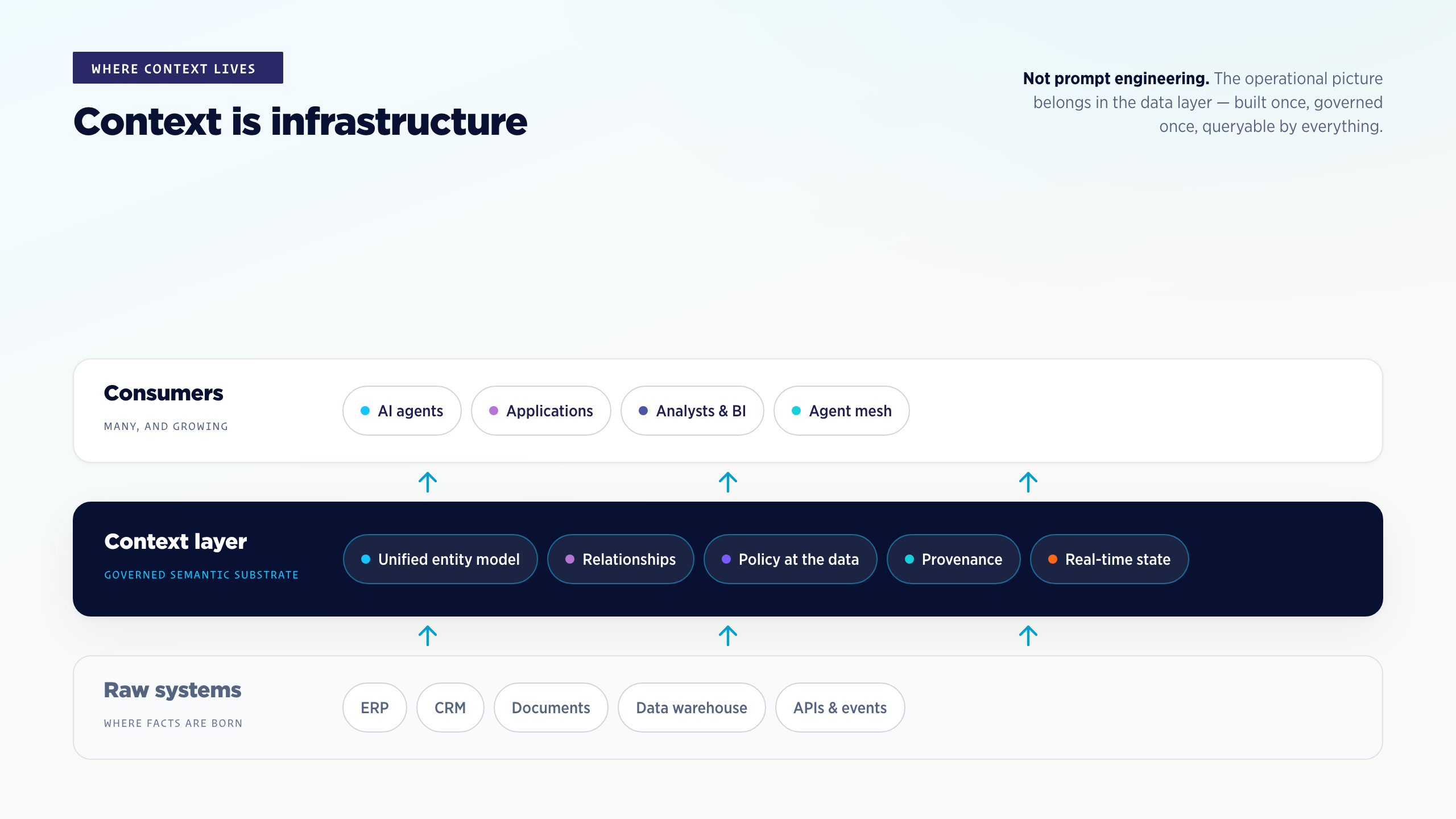
Third, design HITL as a circuit-breaker, not a gate. Plan for the cases that should escalate — low confidence, policy conflict, value thresholds, novel patterns. Build the substrate so the other 95% of cases never reach a person. That is the only path that survives both audit and budget review.
The future of enterprise AI isn’t model-centric. It is context-centric. The organizations that recognize this are building knowledge layers now. The ones that don’t are still arguing about which vector database to standardize on.
Frequently Asked Questions
If you’d like to talk through what a context layer would look like in your stack, get in touch.
Stay in the loop
Weekly insights on enterprise AI, knowledge graphs, and data intelligence.